Esta mañana ha venido a visitarme mi director de departamento a preguntarme si se explicaba algo sobre RAG en la asignatura Recuperación de Información de tercero del grado. Le he dicho que no pero que tenía previsto hacerlo a partir del próximo mes de septiembre. Como prueba de ello publico este vídeo que le pedí a Google LLM que creara a partir de una serie de fuentes de información que nos permiten saber cómo está cambiando el ecosistema de las búsquedas de información tras la irrupción de chatGPT et al. hace poco más de tres años.
RAG: la convergencia entre los motores de búsqueda tradicionales y los Modelos de Lenguaje Extensos (LLM).
RAG son las siglas en inglés de «Generación Aumentada por Recuperación», técnica empleada por las lA para mejorar la precisión de los LLM (modelos de lenguaje extensos) al conectarles fuentes de datos externas y actualizadas antes de generar una respuesta. Su uso reduce alucinaciones y proporciona información contextualizada, siendo ideal para datos privados o de empresa. Esta integración permite superar limitaciones históricas, como la información desactualizada o las respuestas inexactas, al fundamentar la IA en datos específicos y verificables.
LLM y motores de búsqueda
La relación entre los motores de búsqueda y los modelos de lenguaje extensos se define como simbiótica porque ambas tecnologías aprovechan las fortalezas de la otra para superar sus limitaciones individuales, creando sistemas de información más inteligentes y eficientes. Mientras que los motores de búsqueda ofrecen frescura y cobertura masiva de datos, los LLM aportan capacidades de comprensión del lenguaje natural y síntesis de información
LLM y recuperación de información: cambio de paradigma
Esta integración no es solo una mejora incremental, sino un cambio de paradigma hacia servicios de búsqueda centrados en el usuario . Sistemas como el nuevo Bing o Google AI Overviews son ejemplos de esta simbiosis en acción, donde el motor de búsqueda recupera la información más relevante y actual, y el LLM la procesa para ofrecer una interacción fluida y personalizada
La Editorial de la Universidad de Murcia (EDITUM) acaba de estrenar la serie de la Cátedra UNESCO en Gestión de la Información con la traducción del libro ‘Exploring Information Behavior‘ de Tom Wilson, obra de referencia en el campo del comportamiento informacional. Este texto analiza cómo las personas interactúan con la información en distintos contextos. Define la información como una señal modulada y recorre su evolución desde la tradición oral hasta la era digital. A través de diversos modelos teóricos, examina las etapas de búsqueda, los factores psicológicos y sociales implicados, así como las barreras de acceso. También incorpora la dimensión afectiva y fenómenos actuales como la desinformación. Finalmente, ofrece una guía metodológica para investigar cómo se descubre, procesa y utiliza la información en la vida cotidiana.
¿Qué es el comportamiento informacional?
El comportamiento informacional puede entenderse como la interacción humana con las fuentes, canales y contextos de información. Incluye la búsqueda activa, el descubrimiento incidental, el uso, la comunicación, el intercambio y también la evitación de información.
Esta definición es amplia a propósito. No se limita al uso de bibliotecas, bases de datos o buscadores académicos, incorpora también acciones cotidianas como preguntar a otra persona, consultar una web, leer un mensaje, recibir una recomendación algorítmica o decidir no acceder a determinada información.
Idea clave: la información no solo se busca; también se encuentra, se interpreta, se comparte y, en ocasiones, se evita.
La información como señal: una definición operativa
Uno de los planteamientos más interesantes de Wilson es su definición funcional de información como una «señal modulada que puede ser interpretada por un receptor«. Esta idea permite entender la información más allá del documento escrito o del recurso digital.
Desde una señal biomédica en un monitor hospitalario hasta la luz de una estrella analizada por un astrónomo, pasando por el lenguaje oral, el texto impreso o una imagen digital, la información depende de la existencia de un receptor capaz de interpretarla.
Implicación principal: el comportamiento informacional comienza antes de la búsqueda consciente, porque las personas reciben, procesan e interpretan señales constantemente.
El ser humano como animal informacional
Wilson plantea una idea especialmente potente: todas las sociedades humanas han sido siempre sociedades de la información. La llamada sociedad de la información no representa, por tanto, una ruptura absoluta, sino una intensificación tecnológica de una característica estructural de la vida humana.
Desde la tradición oral hasta la escritura, desde la imprenta hasta la web, las sociedades han dependido de la producción, transmisión y conservación de información para sobrevivir, organizarse, aprender y tomar decisiones.
Esta perspectiva permite conectar el comportamiento informacional con procesos antropológicos, sociales, educativos y tecnológicos. La información no es solo un recurso documental: es una condición de la acción humana.
Tipos de comportamiento informacional
El comportamiento informacional adopta formas muy diversas. Puede manifestarse como búsqueda activa, cuando una persona consulta una fuente para resolver una necesidad concreta; como descubrimiento pasivo, cuando recibe información sin haberla solicitado explícitamente; o como interacción social, cuando obtiene o comparte información mediante conversaciones, redes personales o trabajo colaborativo.
En el entorno digital actual, estas formas se mezclan continuamente. Una persona puede iniciar una búsqueda en Google, encontrar información recomendada por una red social, contrastarla con otra persona y terminar utilizando una herramienta de inteligencia artificial para sintetizarla.
Esta complejidad confirma una de las tesis centrales del libro: el comportamiento informacional no es lineal, sino situado, iterativo y dependiente del contexto.
Factores que condicionan el comportamiento informacional
El comportamiento informacional no es uniforme. Está condicionado por factores personales, contextuales y emocionales. Entre los factores personales se encuentran el nivel educativo, la experiencia previa, las competencias informacionales o la percepción de autoeficacia. Entre los factores contextuales destacan el acceso a recursos, el entorno social, la cultura organizativa o las condiciones materiales de búsqueda.
La dimensión emocional también desempeña un papel decisivo. La ansiedad, el miedo, la incertidumbre o la confianza pueden activar, bloquear o modificar la búsqueda de información. Por ejemplo, una persona que recibe un diagnóstico médico puede buscar información de forma intensiva, apoyarse en grupos de ayuda o, por el contrario, evitar información por miedo a lo que pueda descubrir.
Conclusión clave: el comportamiento informacional es situacional, dinámico y profundamente humano.
Modelos de comportamiento informacional
Uno de los aspectos más sólidos de Explorando el comportamiento informacional es que Thomas D. Wilson no construye su propuesta en aislamiento, sino que la inserta dentro de una tradición teórica amplia y acumulativa. Esto permite entender el comportamiento informacional no como un fenómeno único y cerrado, sino como un campo interpretativo en el que convergen distintos modelos, cada uno enfocado en dimensiones específicas del proceso.
El propio modelo de Wilson actúa como marco integrador. En él, la necesidad de información no aparece como un punto de partida abstracto, sino como una consecuencia directa del contexto vital de la persona. Las necesidades informativas emergen de situaciones concretas: trabajo, enfermedad, aprendizaje, toma de decisiones o participación social. A partir de ahí, el modelo incorpora factores intervinientes, como la disponibilidad de recursos, las barreras cognitivas y sociales, la motivación o la autoeficacia, que pueden facilitar o bloquear la búsqueda.
Este enfoque permite entender por qué, ante una misma necesidad, distintas personas adoptan comportamientos completamente diferentes. Una persona puede buscar información en una base de datos especializada, otra puede consultar a un experto y otra puede no buscar nada porque carece de recursos, competencias o confianza suficiente.
Wilson complementa su planteamiento con otros modelos ampliamente consolidados en la literatura. Uno de los más influyentes es el modelo del proceso de búsqueda de información de Carol Kuhlthau, que introduce una dimensión especialmente relevante: la afectiva. Frente a visiones puramente racionales, Kuhlthau muestra que la búsqueda de información está atravesada por emociones cambiantes, desde la incertidumbre inicial hasta la confianza final. Esta incorporación de lo emocional resulta clave para comprender comportamientos reales en contextos de alta implicación personal.
En una línea complementaria, el modelo de Gary Marchionini aporta una visión dinámica del proceso. La búsqueda no se concibe como una secuencia lineal de pasos, sino como una actividad iterativa en la que el usuario reformula continuamente sus estrategias a medida que interactúa con los sistemas de información. Esta idea resulta especialmente actual en entornos digitales, donde explorar, probar, comparar y ajustar la consulta forman parte de la experiencia cotidiana.
Para estructurar conceptualmente estas acciones, Wilson recurre también a la teoría de la actividad desarrollada por Yrjö Engeström. Este enfoque permite descomponer el comportamiento en niveles —actividad, acciones y operaciones— y situarlo dentro de un contexto social determinado. Gracias a esta perspectiva, se evita una simplificación excesiva del comportamiento informacional y se reconoce su carácter situado y contextual.
En el origen mismo del proceso informativo, el modelo de necesidades de información de Robert S. Taylor resulta especialmente esclarecedor. Taylor plantea que la necesidad de información no surge siempre de forma completamente definida, sino que evoluciona desde estados difusos o viscerales hasta formulaciones explícitas. Esta evolución explica por qué muchas búsquedas comienzan con términos vagos o imprecisos y se refinan progresivamente.
Finalmente, Wilson incorpora principios generales como el principio del mínimo esfuerzo formulado por George Zipf. Este principio sostiene que las personas tienden a minimizar el esfuerzo en sus actividades informativas, lo que se traduce en la preferencia por fuentes accesibles o familiares, incluso cuando no son necesariamente las más rigurosas. En el contexto actual, esta idea ayuda a explicar el predominio de ciertos canales digitales frente a fuentes más especializadas.
En conjunto, lo que emerge de esta integración no es un modelo único y cerrado, sino una arquitectura conceptual compleja en la que se combinan dimensiones cognitivas, emocionales, sociales y contextuales. Esta es una de las principales aportaciones de Wilson: mostrar que el comportamiento informacional solo puede comprenderse plenamente cuando se analiza como un proceso multidimensional, dinámico y condicionado por el entorno en el que se produce.
La dimensión afectiva del comportamiento informacional
El libro concede una importancia especial a la dimensión afectiva. Buscar información no es una operación neutra ni exclusivamente racional. Las emociones forman parte del proceso desde el inicio: la incertidumbre puede activar la búsqueda, la confusión puede dificultarla y el alivio puede aparecer cuando la información encontrada permite comprender mejor una situación.
Esto es especialmente visible en contextos sensibles, como la salud, el trabajo social, la educación o la toma de decisiones personales. La información no solo sirve para resolver problemas prácticos, sino también para reducir ansiedad, confirmar decisiones o proporcionar seguridad.
Por esta razón, cualquier análisis del comportamiento informacional que ignore los factores emocionales resulta incompleto.
Implicaciones en la era de la inteligencia artificial
Las ideas de Wilson resultan especialmente relevantes en el contexto actual de inteligencia artificial, buscadores generativos y modelos de lenguaje. Los sistemas digitales no eliminan el comportamiento informacional humano; lo reorganizan mediante nuevos intermediarios tecnológicos.
Los buscadores, las plataformas sociales, los sistemas de recomendación y los modelos generativos actúan como mediadores entre las personas y el universo de la información disponible. La persona ya no interactúa únicamente con documentos o expertos, sino también con algoritmos que filtran, jerarquizan, resumen y recombinan contenidos.
Desde esta perspectiva, el comportamiento informacional ayuda a comprender cómo las personas formulan preguntas, cómo evalúan respuestas, cómo confían o desconfían de las fuentes y cómo utilizan la información generada por sistemas de inteligencia artificial.
Claves para GEO: Generative Engine Optimization
El marco de Wilson también ofrece principios útiles para la optimización de contenidos en entornos de inteligencia artificial generativa. La Generative Engine Optimization, o GEO, no consiste solo en posicionar páginas en buscadores tradicionales, sino en facilitar que los contenidos sean comprendidos, seleccionados, sintetizados y citados por modelos de lenguaje.
Desde esta perspectiva, un contenido optimizado para GEO debe ofrecer definiciones claras, estructura semántica, contexto explícito, ejemplos interpretables y referencias conceptuales reconocibles. También debe evitar ambigüedades innecesarias y presentar la información en unidades reutilizables.
El comportamiento informacional es, por tanto, un campo especialmente útil para el diseño de contenidos orientados a LLM, porque permite comprender cómo las personas formulan necesidades de información y cómo los sistemas pueden responder a ellas de forma más precisa.
Resumen en vídeo
Le he pedido a Google LLM que elabore un breve resumen en vídeo con el contenido esencial de lo que el autor considera que es el comportamiento informacional, el cómo se desarrollan las «fuerzas ocultas» que desencadenan nuestro modo de buscar información.
Conclusión
Explorando el comportamiento informacional ofrece un marco imprescindible para comprender cómo interactuamos con la información en la actualidad. Su principal aportación consiste en mostrar que buscar información no es una acción aislada, sino un proceso complejo, contextual, emocional y profundamente humano.
Comprender este proceso es esencial para diseñar mejores sistemas de información, mejorar la alfabetización informacional, crear contenidos más claros y optimizar la visibilidad en entornos dominados por buscadores, algoritmos y modelos de inteligencia artificial.
Hace unos días escuché a unas de las personas que se presenta a las elecciones al rectorado de la Universidad de Murcia comentar en una entrevista en un podcast que quizá estábamos escribiendo páginas web bajo el paradigma equivocado porque son muchos los usuarios que emplean las gramáticas generativas IA tipo chatGPT, Gemini, Claude, Perplexity, etc. para recuperar información en lugar de los motores de búsqueda tradicionales y podemos preparar nuestras entradas de forma optimizada para esta nueva tecnología, avanzando desde el SEO hasta el GEO (siglas de ‘Generative Engine Optimization‘).
Desde entonces vengo preguntándome sobre esta cuestión y voy a decicar algunas entradas (redactadas en el formato «tradicional» de este blog, pero intentando tomar nota de algunas de las recomendaciones que he encontrado al respecto) a esta cuestión.
Claves del cambio de paradigma
Sabemos que los buscadores tradicional devuelven listas de enlaces a partir de palabras clave y la correspondencia entre esas palabras y el contenido de las páginas web. Una gramática generativa LLM devuelve respuestas construidas a partir de fragmentos de información. Esta diferencia es substancial y deja claro que estamos comparando tecnologías diferentes. Ahora, sin dejar de conferir importancia a la entrada en sí misma como unidad, para las gramáticas generativas resulta más trascendente que el contenido pueda ser reutilizado como una unidad de conocimiento.
1. Credibilidad: si no es verificable, no sirve.
Los modelos generativos priorizan contenidos en los que se puede “confiar”, prefieren textos con fuentes identificables, contenidos con datos concretos y de autoría clara, como se comprueba en esta búsqueda en el modo IA de Google:
Ejemplo de búsqueda en el «modo IA» de Google.
Además de elaborar un resumen para responder a la cuestión, muestra en la parte derecha de la pantalla las fuentes de información que le sirven de soporte. Entre los criterios que necesitamos los autores para ganarnos esa «confianza» destacan:
citar informes, artículos o datasets
incluir cifras, porcentajes o resultados medibles
indicar quién escribe y cuándo
Está claro que cuanto más verificable sea nuestro contenido, más probable es que sea reutilizado. Esto es algo habitual en el mundo científico al escribir un artículo, el mismo debe apoyarse en fuentes de autoridad contrastada que terminan confiriéndole a nuestro trabajo la calidad suficiente para ganar calidad en el seno de la comunidad científica. Esto no es frecuente en la web actual. Por cierto, he usado viñetas en lugar de escribir en un párrafo los criterios «de confianza» para las gramáticas LLM, lo he hecho porque esa forma de exponer el contenido también les parece interesante.
2. Estructura: escribir pensando en fragmentos, no en páginas.
Las gramáticas generativas no “leen artículos”, trabajan con fragmentos (‘chunks‘). Los autores podemos, fácilmente, ayudar a ello usando los encabezados (H1, H2, H3, …) de una forma clara y consistente (de hecho, cualquiera que siga este blog verá que hay más encabezados que de costumbre, antes no hacía tanto uso de ellos). Dividir el contenido en bloques pequeños y evitar referirnos a esos bloques (párrafos) con expresiones ambiguas del estilo de “esto último permite” o “lo anterior indica” servirá para aumentar el interés de esas gramáticas hacia nuestra entrada web, esto no contradice para nada lo que hemos venido haciendo hasta ahora. La novedad fundamental reside en estructurar en formato pregunta–respuesta estos fragmentos de información, por ejemplo:
Formato de redacción «pregunta-respuesta» en una entrada web.
Este tipo de bloques de contenido encaja perfectamente con cómo funcionan los sistemas RAG (Retrieval-Augmented Generation), técnica que mejora la precisión de los modelos LLM en la consulta de fuentes de datos externos.
3. Claridad: menos retórica, más información.
Para un lector humano, cierto grado de estilo es positivo, aunque siempre se ha comentado que la web no es el lugar para perífrasis y circunloquios. Para una gramática generativa LLM lo importante es encontrar contenidos con:
frases claras
conceptos explícitos
poca ambigüedad
Asím funciona mejor la frase «Un eclipse solar ocurre cuando la Luna bloquea la luz del Sol desde la Tierra” que el texto «Este fenómeno sucede cuando se alinean ciertos cuerpos celestes”. Redactar sencillo genera contenido de fácil comprensión y mayor reutilización. La clave es la densidad informativa (cuánta información útil y concreta hay en una frase o texto en relación con su longitud).
4. Metadatos para ayudar a las máquinas a entender el contenido.
Si bien no es obligatorio, añadir metadatos estructurados, lo cierto es que ayuda bastante. Aquí entramos en el territorio de Schema.org y de los datos estructurados que sirven para indicar (entre otras cosas):
tipo de contenido (artículo, dataset, etc.)
autor
fecha
tema
Este enriquecimiento de los sitios web con microdatos reduce la ambigüedad del texto y mejora la interoperabilidad con sistemas externos. En este caso, esto es positivo tanto para las gramáticas generativas como para la recuperación de información tradicional.
5. Pensar en RAG: cómo “leen” realmente estos sistemas.
Muchos sistemas actuales combinan modelos de lenguaje con recuperación de información RAG. Esto implica:
el contenido se fragmenta
el contenido se convierte en vectores (‘embeddings‘)
del contenido se van a recuperar los fragmentos más relevantes
el modelo genera la respuesta
Lo cierto es que los autores no podemos controlar este proceso, pero sí facilitarlo por medio de:
bloques de contenido de tamaño medio (ni demasiado largos ni demasiado cortos)
repetir ligeramente conceptos clave (sin forzar)
responder preguntas que el usuario realmente haría
Lo cierto es que las dos primeras recomendaciones también son válidas para la recuperación de información tradicional, es la tercera (que ya hemos adelantado) la que representa una novedad: escribir pensando en preguntas concretas.
6. Qué ya no funciona (o funciona peor)
Algunas prácticas del SEO clásico pierden sentido aquí:
keyword stuffing (uso excesivo de palabras clave) → irrelevante o incluso perjudicial
textos largos sin estructura → difíciles de reutilizar
contenido genérico sin datos → baja probabilidad de uso
Tanto el exceso de palabras clave como la desestructuración de los textos sabemos desde hace tiempo que estaba penalizado en la recuperación de información clásica. En el contexto GEO podemos considerar su abolición como una premisa. En GEO, más no es mejor: mejor es mejor.
Resumiendo …
Todo esto se puede resumir así en una frase corta: «No escribas páginas. Diseña unidades de conocimiento«. Para ello, debemos seguir, como mínimo, esta serie de pasos:
Hacer el contenido verificable (fuentes, datos, autoría).Q
Estructurar el texto en bloques claros (mejor si son preguntas y respuestas).
Escribir de forma explícita y sin ambigüedades.
Facilitar la fragmentación del contenido (‘chunking’).
La optimización del contenido para las gramáticas generativas no sustituye completamente al SEO, lo que hace es añadir una nueva capa.
Para finalizar, le he pedido a Google Notebook LLM que prepare un pequeño vídeo para mostrar la transición del SEo al nuevo paradigma GEO a `partir de algunas de las fuentes que hemos empleado para preparar esta entrada. Creo que ha quedado interesante.
El camino hacia la ciencia abierta amplía el foco de la comunicación científica hacia un nuevo paradigma: ya no se trata de publicar en abierto los artículos científicos para exponer y difundir los resultados de investigación, sino también de hacer públicos y accesibles los conjuntos de datos que sustentan la investigación. Estos conjuntos (o ‘datasets’ en la jerga) se han convertido en un elemento fundamental para mejorar la transparencia en la investigación (y la rendición de cuentas), facilitar la reproducibilidad y permitir la reutilización del conocimiento científico.
En nuestro contexto, el repositorio Zenodo desempeña un papel clave dentro de las infraestructuras de ciencia abierta. Desarrollado por el CERN (donde nació la web) y financiado por la Comisión Europea, permite depositar ‘datasets’, software, documentos y otros resultados de investigación, asignándoles un DOI que facilita su citación, preservación y difusión.
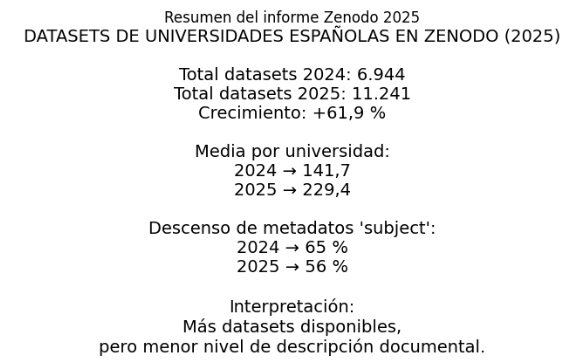
Hace un año (más o menos) analizamos en este blog la presencia de datasets generados por investigadores adscritos a las universidades públicas españolasen Zenodo (en las privadas se investiga menos). En ese estudio, con fecha de 31-12-2024, identificamos 6.944 contribuciones institucionales de conjuntos de datos y aportaba dos conclusiones principales: (1) el crecimiento progresivo del depósito de datos desde el año 2020 y (2) la existencia de grandes diferencias entre universidades en cuanto a su participación en este tipo de repositorios.
Hace pocos días, finalizamos un nuevo informe, actualizado hasta 31-12-2025, que confirma la aceleración de este depósito. En un año, el número total de conjuntos de datos de investigación asociados a investigadores de universidades públicas españolas ha pasado de 6.944 a 11.241 (62% de incremento). Esto refleja un cambio progresivo en las prácticas de investigación, impulsado tanto por políticas institucionales (ENCA) como por los requisitos de financiación y evaluación relacionados con la ciencia abierta. El hecho de que ANECA también los valore como mérito para sexenios y acreditación puede tener algo que ver, aunque quizá el efecto sea muy reciente.
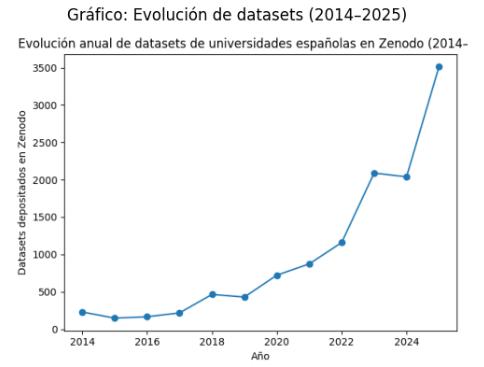
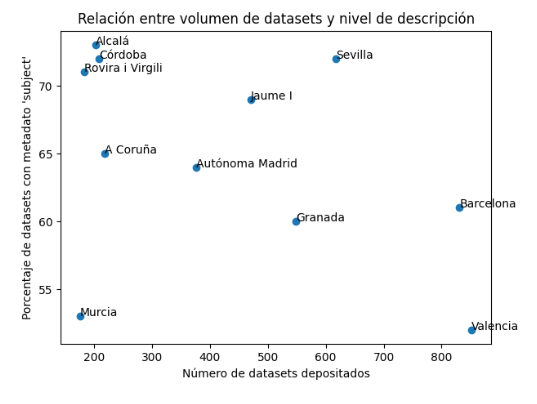
Crece muy rápido el depósito de datos
La evolución anual muestra una tendencia claramente ascendente, especialmente a partir de 2020.
El pasado año 2025 destaca por el fuerte incremento de los conjuntos de datos de investigación depositados, que supera con mucho los valores registrados en años anteriores. Este crecimiento sólo es posible por la asunción por parte de los investigadores de la necesidad de considerar el depósito de los datos como parte natural del ciclo de investigación (además de la «obligación» que hay cuando recibimos financiación pública). El crecimiento no se concentra en unas pocas universidades, ha sido generalizado (incluso en aquellas que forman parte del «furgón de cola»). La media por universidad ha pasado de 141 a 229 conjuntos de datos, mientras que la mediana prácticamente se duplica. Esto significa que el depósito se extiende progresivamente por el conjunto del sistema universitario español.
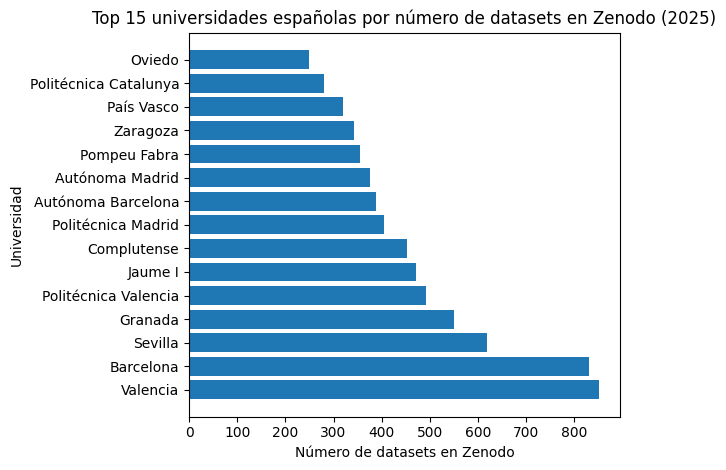
Se observa un aumento significativo del número de universidades de alta actividad. Si en 2024 solo dos superaban los 400 conjuntos de datos, en 2025 ya son siete, destacando especialmente Valencia, Barcelona, Sevilla, Granada y la Politécnica de Valencia. Esto apunta a la consolidación y aceptación de estrategias institucionales más activas en lo relacionado con la gestión de datos de investigación.
Más conjuntos de datos, pero menos descripción
Los datos de este nuevo informe confirman una tendencia negativa: a medida que aumenta el volumen de conjuntos de datos depositados, la calidad de su descripción documental disminuye. Se ha utilizado como indicador la presencia del metadato ‘subject‘ en la descripción del conjunto de datos porque permite describir su contenido y facilita su posterior recuperación en el repositorio. En 2024, aproximadamente el 65 % incluían este tipo de metadatos, mientras que en 2025 la media desciende hasta un 56 %, quedando muy lejos en el tiempo aquellos años en los que este porcentaje alcanzaba el 75%. Esta tendencia a la baja sugiere que el crecimiento del volumen se produce más rápido que la adopción de buenas prácticas de documentaciónde los conjuntos de datos. Aunque cada vez se depositan más, no siempre se acompañan de una descripción suficiente que facilite su localización y reutilización.
Un indicador para analizar el equilibrio entre volumen y calidad
En el primero de los informes introdujimos un indicador sintético inspirado en la medida I₀ de Borko, originalmente diseñada para evaluar la eficacia de sistemas de recuperación de información, y que adaptamos a este contexto (lo denominamos igual un poco en «homenaje» a esta medida que utilizamos en nuestra tesis doctoral en una época muy, pero que muy lejana, el año 2002). Esta medida combina dos dimensiones: el volumen de conjuntos de datos depositados por cada universidad y el nivel de descripción documental de los mismos. Según este indicador, las que muestran un mejor equilibrio entre ambas dimensiones en 2025 son Sevilla, Jaume I, Barcelona, Autónoma de Madrid y Alcalá, que ocupan las primeras posiciones del ranking.
Conclusión
Los resultados muestran que el ecosistema de conjuntos de datos de investigación en el sistema universitario español crece con rapidez. Cada vez más investigadores efectúan el depósito en abierto en repositorios y varias universidades comienzan a consolidar estrategias institucionales para la gestión de datos. Sin embargo, el crecimiento cuantitativo debe ir acompañado de mejoras en la documentación y descripción de los conjuntos de datos. Si no se incorporan los metadatos adecuados, estos conjuntos de datos pueden ser técnicamente «abiertos», pero serán difíciles de encontrar, interpretar o reutilizar, para ello no hace falta el depósito.
El reto de los próximos años no será solo publicar más conjuntos de datos de investigación, sino también describirlos y publicarlos mejor.
Fuentes:
Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2023). Implementación de los repositorios de datos de investigación en las universidades públicas españolas: estado de la cuestión. Scire: representación y organización del conocimiento, 29(2), 39-49. https://doi.org/10.54886/scire.v29i2.4914
Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2023). (2025). #datasets de universidades españolas en Zenodo – 2024. Zenodo. https://doi.org/10.5281/zenodo.18085406
Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2026). #datasets de universidades españolas en Zenodo a 31-12-2025. Zenodo. https://doi.org/10.5281/zenodo.18903560
Nota técnica.
Cuando en un conjunto de datos de investigación aparecen investigadores de dos o más universidales, ese conjunto de datos se computa en cada institución. Por tanto, el número de conjuntos de datos total es algo inferior al que mostramos.
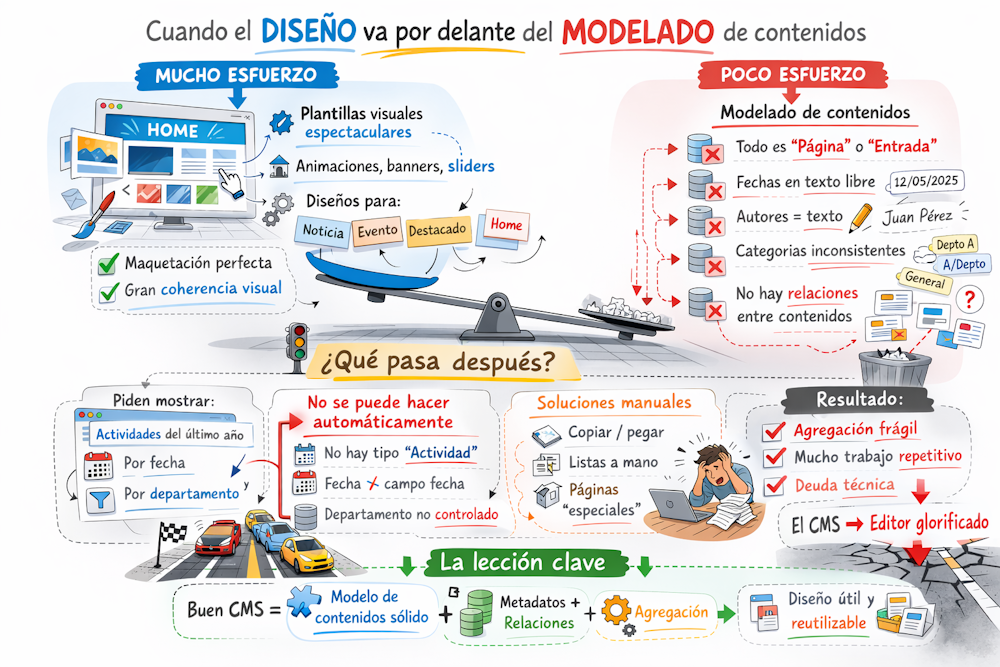
Aprovecho que estoy preparando las clases de esta semana en la asignatura «Sistemas de Gestión de Contenidos» del 2º curso del grado en Gestión de Información y Contenidos Digitales para reflexionar brevemente sobre una cuestión: ¿qué pasa cuando se dedica muchas horas a un diseño «muy visual» del sitio web con nuestro CMS y «pasamos» un poco (o un bastante) del modelado del contenido?.
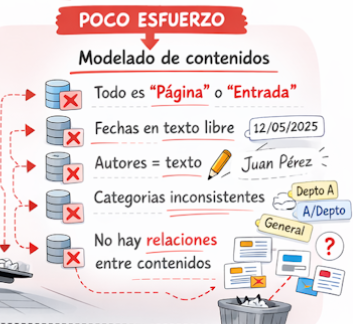
No es raro encontrarnos sitios web donde se ha puesto todo el interés en un diseño visual muy atractivo que atrae, sin duda alguna, a nuevos usuarios pero que, a nivel de modelado de contenidos, presenta graves problemas. Cuando el diseño va por delante, nos centramos en el desarrollo de unas plantillas visuales espectaculares, animaciones, banners y carruseles de diapositivas de gran calidad visual, maquetación de la interfaz web atractiva, todo ello dentro de una gran coherencia visual (el «tema» del CMS).
Si el sitio web no va más allá de un blog, un pequeño catálogo de productos o una pequeña web institucional, no se plantearían muchos problemas. En estos casos, puede resultar suficiente con los tipos de contenido base «página» y «entrada» (‘post’), con introducir las fechas en formato de texto libre («12/06/2025» o «12-jun-26», a elección del usuario incluso), no tener normalización alguna de cómo introducir el nombre de un autor de un libro («Juan Antonio Pérez López» o «Juan A. Pérez López» o «Pérez López, Juan Antonio»), que la taxonomía del sitio web no esté muy trabajada (o sin trabajar directamente, dejando a los usuarios construirla sin consistencia alguna) y, finalmente, no existe relación entre tipos de contenido específicos (básicamente por su escasez o ausencia). En definitiva, mucho diseño y poca gestión de información, algo parecido a lo que le está ocurriendo ahora al equipo Aston Martin de F1, que ha contratado un «mago» del diseño como Adrian Newey y unos motores Honda que no son capaces de llevar a cabo quince vueltas seguidas a un circuito.
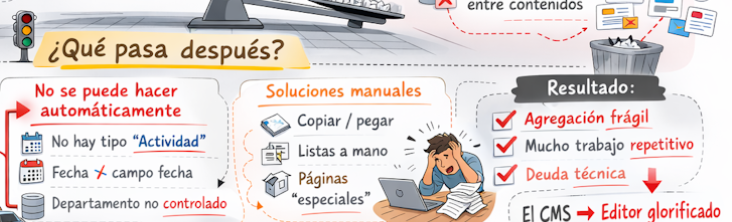
En estos sitios web, poco más se puede hacer que navegar por las distintas secciones, usar el buscador o esperar que la nube de etiquetas esté construida con algún criterio. Si quisiéramos consultar un histórico de «actividades culturales»desarrolladas en el último año, tendríamos el problema de que no existe ese tipo de contenido específico y que, además, la búsqueda por fechas puede resultar complicada al no esta normalizado el formato de entrada.
La solución suele terminar siendo manual, se copia contenido de entradas que recuperamos (manualmente casi siempre) de la web para pegarlo en listas elaboradas a mano (como si trabajáramos con el editor de texto normal, de ahí el apelativo de «glorificado» de la imagen). El resultado final es escasa y frágil agregación de contenidos (poco se puede extraer por medio de consultas automáticas), mucho trabajo repetitivo, algo que debería obviar el uso de un CMS, produciéndose una situación de «deuda técnica», algo parecida a la que Honda tiene ahora con la escudería Aston Martin y con todos los aficiones a la Fórmula 1 que ven que Fernando Alonso difícilmente podrá aspirar a un podio en esta su última temporada (o no) en los circuitos.
Siguiendo con esta metáfora, hay que intentar que el diseño del CMS no nos obligue con un coche normal en las carreras. Para ello hace falta modelado de contenido adeucado, metadatos bien definidos, relaciones entre tipos de contenidos, vistas del contenido a partir de agregación, todo ello en un marco de diseño web útil y reutilizable.
Actualizo una entrada de noviembre en 2019 sobre el «Contrato para la Web» que puso en marcha el inventor de todo esto, Sir Tim Berners-Lee, para intentar asegurar que internet debe seguir siendo un bien público para toda la sociedad.
«La web se diseñó para unir a la gente y hacer que el conocimiento fuese accesible para todos y todas. Ha cambiado el mundo para bien y ha mejorado la vida de miles de millones de personas. Sin embargo, todavía hay muchas personas que no pueden acceder a sus ventajas y muchas otras para las que la Web supone un coste demasiado elevado.
Todos tenemos un papel que cumplir a la hora de salvaguardar el futuro de la Web. Los representantes de más de 80 organizaciones redactaron el Contrato para la Web en nombre de gobiernos, empresas y la sociedad civil. En él se establecen los compromisos que deben guiar las políticas digitales. Con el fin de alcanzar los objetivos del Contrato, los gobiernos, las empresas, la sociedad civil y las personas deben comprometerse con el desarrollo sostenido de dichas políticas, así como con la defensa y la implementación de este texto».
Luchar por la web para que siga siendo abierta y un recurso público global para las personas de todo el mundo, ahora y en el futuro.
Estos principios afectan («reclaman» más bien) a gobiernos, empresas y ciudadanos. Están dirigidos a gran parte (a lo mejor a toda) de la sociedad actual. Asegurar que la red tenga infraestructura suficiente, que el acceso sea lo más barato posible, que se respeten los derechos de los usuarios y que su uso esté dirigido a mejorar a las personas, son causas por las que vale la pena postularse, más allá de rellenar el formulario de adhesión y hacer clic con el dedo en la pantalla del teléfono.
Actualización a fecha de 2026.
Portada de la declaración
Al momento de su lanzamiento, gobiernos como Francia y Alemania se sumaron a la iniciativa. El gobierno alemán anunció su apoyo a la iniciativa en noviembre de 2018, destacando internet como un «bien público» y un derecho fundamental que debe ser protegido, asegurando el acceso para todos y respetando la privacidad. El gobierno francés también se adhirió a la iniciativa en términos similares. Además, la Unión Europea se ha alineado estrechamente con los principios básicos dictados por Berners-Lee, al igual que los esfuerzos conjuntos de Estados Unidos y otros 60 países firmantes de la «Declaración para el Futuro de Internet«, que busca un internet abierto, seguro y libre. Países como Ghana y Brasil han tenido intervenciones directas apoyadas por la Web Foundation para mejorar la asequibilidad y los derechos digitales.
En el caso brasileño,apoyó activamente el desarrollo y aprobación del Marco Civil da Interneten Brasil, considerado el primer «proyecto de ley de derechos» de internet en el mundo. Esta legislación consagraba derechos fundamentales como la neutralidad de la red, la privacidad y la libertad de expresión. En Ghana, la fundación trabajó para abordar la brecha digital, particularmente la brecha de género, a través de la red Women’s Rights Online (WRO). Esto incluye la promoción de políticas de TIC que sean sensibles al género, fomentando el acceso a internet asequible y garantizando los derechos digitales de las mujeres.
Las políticas públicas influenciadas por el contrato se centran en los tres pilares de gobierno del documento:
1. Asegurar la conectividad (acceso): Políticas destinadas a reducir la brecha digital y garantizar que todo el mundo pueda conectarse a internet, haciendo que sea asequible y accesible.
2. Mantener la red abierta (neutralidady disponibilidad): Normativas que prohíben el cierre o la censura total de internet por parte de los gobiernos.
Principales aliados tecnológicos: Más de 150 organizaciones respaldan la iniciativa, incluyendo grandes tecnológicas como Google, Facebook (Meta), GitHub, Reddit y DuckDuckGo, que han ajustado sus políticas de producto a estos principios.
Actualizo una entrada antigua de este blog que escribí en el año 2006 sobre la cierta confusión existente sobre si, en una búsqueda, recuperamos información o datos. Vamos a ver cómo queda.
En el campo de la recuperación de información (‘information retrieval‘), casi al principio de la disciplina, era normal encontrar autores que empleaban la expresión «recuperación de datos» cuando en realidad de lo que estaban hablando era de recuperar información. Teniendo en cuenta las fechas de lasque hablamos (años 80, cuando el tecnopop), Esto se debía, fundamentalmente, a una clara influencia de la terminología informática, disciplina cuya rapidísima evolución llevó a muchos autores a cometer el error de considerar sinónimos ambos conceptos, llegándose a olvidar, como afirmaba Brookes, que se puede recuperar información sin emplear procedimientos informáticos (hecho indiscutible aunque no sea lo más común hoy en día, evidentemente).
El frecuente y necesario empleo de una tecnología no sustituye la obligatoriedad de utilizar adecuadamente los conceptos terminológicos. Un ejemplo de este desacierto lo hallamos en el Glosario ALA que define “information retrieval” como “recuperación de la información» en su primera acepción y como “recuperación de datos” en una segunda, considerando sinónimos ambos términos en lengua inglesa. De parecida opinión es el Diccionario Mac Millan de Tecnología de la Información, que considera la recuperación de información como el conjunto de “técnicas empleadas para almacenar y buscar grandes cantidades de datos y ponerlos a disposición de los usuarios”.
Afortunadamente, es mayor el grupo de autores que establecen diferencias entre ambos conceptos. Entre ellos destaca Meadow, para quien la recuperación de la información es “una disciplina que involucra la localización de una determinada información dentro de un almacén de información o base de datos”. Este autor establece de forma implícita una ligazón entre recuperación de información y el concepto de «selectividad» a la hora de presentar esa información al usuario siguiendo algún tipo de criterio discriminatorio (selectivo por tanto) entre una gran colección de documentos. Meadow marca un poco más estas diferencias, al afirmar que no es lo mismo la recuperación de información entendida como traducción del término inglés information recovery que cuando se traduce el término information retrieval, porque “en el primer caso no es necesario proceso de selección alguno”. Pérez-Carballoy Strzalkowski refuerzan esta idea afirmando que “una típica tarea de la recuperación de información es traer documentos relevantes desde una gran archivo en respuesta a una pregunta formulada por un usuario y ordenar estos documentos de acuerdo con su relevancia”.
Grossman y Frieder indican que la recuperación de información es “hallar documentos relevantes, no encontrar simples correspondencias a unos patrones de bits”. De similar criterio es el W3Cque define recuperar información como “dado un conjunto de documentos y una pregunta, encontrar el conjunto de documentos más relevantes con la pregunta”.
En clase, explico a mis estudiantes que, en la recuperacíón de datos, las preguntas son altamente formalizadas y la respuesta es directamente toda la información deseada. Así, “recuperar los títulos de los libros escritos por Jorge Luis Borges en la década de los 50” sería la ecuación “SELECT titulo WHERE autor=’Jorge Luis Borges’ AND fecha>1949 AND fecha<1960”. Otra pregunta fácil es saber cuántos ciudadanos de Murcia tienen alguna multa de tráfico sin abonar al Ayuntamiento de la ciudad y cuánto totaliza esa deuda para las arcas municipales. Nos movemos en un paradigma determinista, el territorio del modelo relacional de bases de datos. También les explico que en la recuperación de información, las preguntas son más difíciles de trasladar a un lenguaje formal y la respuesta es un conjunto de documentos que probablemente contendrá la información deseada, siempre con un factor de cierta indeterminación. En este modelo, el territorio de los SRI, La consulta sería, por ejemplo, «Obras Borges década 50”.
El gran profesor ‘Keith’ Rijsbergen establece en la siguiente tabla las diferencias entre recuperar datos e información:
Finalizo siempre esta cuestión presentando la siguiente cita de Ricardo Baeza-Yates:
“dada una necesidad de información (consulta + perfil del usuario + … ) y un conjunto de documentos, ordenar los documentos de más a menos relevantes para esa necesidad y presentar un subconjunto de aquellos de mayor relevancia”
¿Sigue este tema vigente?
Creo que esta distinción conceptual sigue siendo especialmente pertinente hoy en día. Si se observa la evolución reciente de los sistemas de búsqueda y acceso a la información. Las tecnologías actuales —como la búsqueda semántica, el uso de representaciones vectoriales (embeddings) o los modelos de lenguaje de gran tamaño (LLMs)— no han eliminado el problema clásico de la recuperación de información, sino que han añadido nuevas capas de complejidad. Estos sistemas ya no se limitan a la coincidencia literal entre términos (‘matching‘), sino que operan sobre representaciones semánticas del contenido, aproximándose con mayor eficacia a la noción de relevancia, aunque sin resolverla plenamente.
Datos, información y recuperación en sistemas de búsqueda actuales. Imagen elaborada por chatGPT.
Muchos de los SRI contemporáneos combinan, de forma híbrida, procedimientos propios de la recuperación de datos y de la recuperación de información. La indexación estructurada, las búsquedas exactas o las consultas sobre bases de datos conviven con mecanismos de ranking, inferencia semántica y estimación de relevancia. Esta convergencia tecnológica no invalida la distinción conceptual entre ambos enfoques; al contrario, la hace más necesaria, ya que permite comprender mejor los límites, fortalezas y riesgos interpretativos de cada tipo de sistema. En este contexto, los sistemas basados en modelos de lenguaje de gran tamaño y arquitecturas de retrieval-augmented generation (RAG) reintroducen, bajo nuevas formas, el debate clásico entre datos e información. Aunque estos modelos pueden generar respuestas coherentes y contextualmente plausibles, su funcionamiento depende en gran medida de procesos previos de recuperación y selección de documentos relevantes. La calidad informativa del resultado no reside únicamente en la capacidad generativa del modelo, sino en la adecuación del proceso de recuperación que lo alimenta, confirmando la vigencia de los principios fundamentales de la recuperación de información.
Fuentes bibliográficas.
[1] Brookes afirma esto en la presentación del primer capítulo de la obra Information Retrieval Research titulado ‘Information Technology and Information Science’, donde recuerda que el problema de la recuperación de información no ha de aplicarse sólo a lo automático, sino también a lo manual. (Oddy et al, 1981). Salton también lo recalca al comentar que no siempre se recupera información textual (Salton & McGill, 1983).
CRIS son las siglas de ‘Current Research Information System‘ (sistemas de información de investigación), plataformas que representan un pilar esencial para que las instituciones de investigación adopten plenamente la estrategia de la Ciencia Abierta. Su importancia va más allá del registro de la producción científica —como artículos, capíutlos de libros o proyectos— ya que operan como una infraestructura de metadatos que lleva a cabo la conexión entre personas, publicaciones, datos, financiación e impacto de la investigación, facilitando la trazabilidad, visibilidad, interoperabilidad y reutilización del conocimiento. En un contexto en que las agencias financiadoras, las universidades y los repositorios convergen hacia la apertura, la transparencia y la responsabilidad en la investigación como pilares del tránsito a la Ciencia Abierta, los CRIS permiten que esa transformación se realice de forma sistemática y estructurada.
El CRIS como elemento conector en el contexto de la Ciencia (imagen elaborada con chatGPT).
Un aspecto central del valor de un CRIS es su capacidad para articular el ciclo completo de la investigación: desde la financiación y la planificación de proyectos hasta la publicación, el depósito de datos, la transferencia y la evaluación. Esta visión sistémica favorece que las instituciones puedan cumplir con mandatos de acceso abierto y datos abiertos (por ejemplo, enlazando las publicaciones con sus versiones en repositorio o monitoreando embargos), que gestionen resultados más allá del artículo tradicional (conjuntos de datos de investigación, código de software libre, materiales docentes, etc.) y que generen métricas e informes para evaluación responsable. En este sentido, el CRIS actúa como una “capa de información contextual”: quién, qué, cuándo, con qué financiación, bajo qué proyecto, qué impacto, etc., mientras que los repositorios suelen limitarse de la preservación y difusión del objeto digital.
A nivel internacional encontramos ejemplos de CRIS que ilustran tanto el modelo como su relación con la Ciencia Abierta. Por ejemplo, el sistema nacional noruego CRIStin (Current Research Information System in Norway) permite documentar toda la producción académica de los investigadores noruegos y complementa su uso para evaluación del sistema de investigación público.
En Finlandia, Alemania y los Países Bajos también se han desarrollado modelos nacionales de gestión de la información de investigación, como documenta el informe de OCLC Research. También en Europa, la asociación euroCRIS promueve el estándar CERIF (Common European Research Information Format) con el fin de asegurar la interoperabilidad entre los CRIS.
Estos ejemplos muestran cómo los CRIS institucionales y nacionales se integran en un ecosistema mayor de datos e infraestructuras de Ciencia Abierta. En el caso de un país que adopte un CRIS nacional o regional, la ventaja es que se construye una infraestructura homogénea para la agregación de datos de múltiples instituciones, lo cual permite realizar análisis nacionales, comparativos y soportar políticas de Ciencia Abierta a gran escala.
En España, los CRIS institucionales de las universidades funcionan en estrecha relación con los llamados “portales de investigación” públicos, es decir, las interfaces visibles donde se exponen perfiles de personal investigador, grupos, publicaciones, proyectos y métricas. Dichos portales, alimentados por la base de datos de Dialnet y por el CRIS de cada institución académica, permiten la visibilidad institucional y cumplen una función de transparencia hacia la sociedad. La integración entre CRIS y portal es clave: el primero organiza, vincula y valida los metadatos, el segundo los presenta al público de forma navegable.
Este marco es fruto del Proyecto Hércules, impulsado por Crue Universidades Españolas, que proponía una arquitectura semántica común para los CRIS universitarios españoles, basada en estándares compartidos, ontologías alineadas y una solución de gestión de la investigación común. El resultado final facilita que los datos de diferentes universidades se puedan comparar, agregar y explotar de forma interoperable. Sin duda alguna, la clave de bóveda de este proyecto ha sido el papel de Dialnet, si el trabajo previo de esta fundación, todo el desarrollo de este proyecto hubiera resultado valdío. Una vez más se demuestra la frase de Bill Gates: ‘content is king‘. Poco a poco, se van implementando los portales de investigación de las universidades españolas y se está configurando un sistema de información científica agregado que puede asumir funciones similares a las de un CRIS colectivo para aquellas instituciones que no cuentan con soluciones propias completas. Estas plataformas son elementos articuladores de un ecosistema de investigación abierta, interoperable y de alcance cada vez mayor. A nivel internacional, los sistemas que adopten el estándar CERIF muestran cómo la gestión de la información investigadora se ha transformado en una infraestructura de infraestructuras (“infraestructura de segundo orden”) para la Ciencia Abierta. En España, esta convergencia entre CRIS, portales de investigación y plataformas cooperativas como Dialnet, señala una evolución hacia un modelo más integrado, transparente y orientado al bien público del sistema de investigación.
Las universidades de Sheffield (la de nuestro «Tío Tom» tenía que ser), Lancaster y Surrey decidieron rechazar un nuevo acuerdo de suscripciones ‘read and publish‘ y abandonan la suscripción masiva de revistas científicas con Elsevier.
Esta decisión está impulsada por restricciones financieras de estas instituciones y por la demanda de mejores condiciones de acceso abierto, pone de manifiesto la creciente presión sobre los costes de suscripción a las revistas científicas de alto nivel. Las editoriales privadas venden paquetes completos de este tipo de publicaciones, junto con otros servicios y productos, elevando los costes hasta cantidades que representan un esfuerzo, no siempre justificado en términos de aprovechamiento, para las instituciones de educación superior.
Estas tres universidades se unieron a un grupo creciente en el Reino Unido (York, Essex, Kent y Sussex, entre otras) que optaron por priorizar modelos sostenibles centrados en el acceso abierto (¡el de verdad! no el que firman las universidades españoles a través de CRUE y con ayuda del ministerio), frente a los paquetes tradicionales «todo incluido» que ofrecen las grandes editoriales de pago y que se convierten en insostenibles en épocas donde la inversión en lo público se reencamina más hacia gastos militares que hacia la mejora de la financiación de las universidades públicas.
Préstamo interbibliotecario de «alta velocidad». Es la «joya de la corona» de su estrategia, se ha optimizado el préstamo para que los investigadores puedan solicitar artículos específicos que ya no están bajo suscripción. El éxito se basa en la rapidez (entregas digitales en menos de 30 minutos en muchos casos) y búsqueda ampliada (plataformas como StarPlus de Sheffield que permiten buscar más allá de la colección propia y generar solicitudes automáticas).
Suscripciones selectivas y acceso histórico: las universidades «no cortan el grifo» por completo. De hecho, sus bibliotecas mantienen títulos individuales (se seguirá pagando de forma independiente por las revistas de Elsevier que tengan el mayor uso e impacto real en su comunidad) y se mantiene acceso post-cancelación (se conserva el derecho a leer artículos publicados durante los años en que la suscripción estuvo activa).
Fomento del uso de software que rastrea versiones gratuitas y legales de los artículos, recomendando las extensiones del navegador comoLibKey Nomad o sistemas como Unpaywall que detectan si un artículo tiene una versión en abierto mientras el usuario navega.
Uso intensivo de los repositorios institucionales impulsando sus propios archivos digitales (como White Rose Research Online) donde los autores depositan sus manuscritos aceptados.
Las universidades de Surrey y Lancaster han implementado políticas de «Rights Retention«. Esto obliga a sus investigadores a mantener la propiedad intelectual de sus manuscritos para que puedan subirse a la web de la universidad inmediatamente, sin esperar a que la editorial levante el «muro de pago».
Alternativas implantadas en la Universidad de California para «superar» el fin de las suscripciones masivas a Elsevier y otras editoriales. Fuente: Universo Abierto.
Es posible que a los mayores les suene este modelo de acceso a la literatura científica (que podríamos llamar «bajo demanda»). De alguna manera, reproduce el cómo se accedía a los artículos a principios de este siglo, con una visión algo más actual en cuanto al uso de la tecnología donde la Ciencia Abierta comienza a abrirse paso. Si esto funcionaba antes del tremendo derroche acometido por universidades y autoridades gubernamentales que lo han financiado. Es muy posible que el rendimiento y la excelencia investigadora no vayan a sufrir deterioro alguno y, teóricamente, se podrán dedicar esos recursos a financiar más y mejores equipos de investigación, en lugar de, literalmente, regalarlos a editoriales privadas como Elsevier, cuando no a editoriales directamente depredadoras.
El avance científico no se va a detener, seguro que siempre habrá alguien que pueda ver más allá porque está aupado sobre los hombros de muchos sabios que le han precedido (Newton dixit). Y quizá deberíamos volver a confiar en las bibliotecas que siguen estando ahí, internet no las jubiló (aunque para muchos así lo haya parecido).
Pedro Manuel – así le llamaba su madre – era profesor de Tecnologías de la Información en nuestra Universidad desde 1989. Logró la titularidad en el año olímpico de 1992. Su docencia, en almacenamiento y acceso a la información, la desarrolló en nuestra facultad y también en la de Informática, el centro donde se formó en los años ochenta (nos formamos para ser correctos, somos compañeros de promoción, además de amigos desde esos días), como diplomado universitario. Años después, como también hice yo aunque en otra universidad, cursó la licenciatura en Documentación en la Universidad Politécnica de Valencia y los estudios de doctorado en nuestra universidad). Miembro del grupo de investigación en Tecnologías de la Información, participó en varios proyectos de transferencia. En el más reciente, e-labor@, analizamos la necesaria transformación digital en las entidades del Tercer Sector de Acción Social (TSAS). Resultado de este proyecto es el informe La transformación digital de entidades del Tercer Sector de Acción Social: un marco para la gestión documental, donde es autor del capítulo “Prospectiva de sistemas de gestión documental: factores claves para entidades TSAS”, dedicado a presentar la gestión documental actual y los sistemas que la implementan y que hemos reeditado en formato de artículo en el último número de la revista (sección de Estudios y Experiencias). Fue vicedecano de la facultad en varios equipos directivos y a él le debemos, entre otras cosas, el seguimiento de la construcción del edificio tan bonito que alberga nuestra facultad, una de las más dinámicas y creativas de la Universidad de Murcia.
Su relación con nuestra revista se remonta a los inicios de nuestra singladura, Pedro Manuel formó parte del primer comité editorial asumiendo la secretaría del mismo en ese y otros períodos. También fue el responsable del diseño de la maquetación de la edición impresa estableciendo (a nivel interno) las primeras normas, formatos y flujos de trabajo para la publicación de los artículos y de otras secciones de la revista. La solidez, claridad y pertinencia de estos criterios son tales que muchas de esas recomendaciones e instrucciones continúan plenamente vigentes hoy, veintiocho años después, con Anales de Documentación plenamente integrada en el ecosistema digital de la comunicación científica.
Precisamente, toda la tarea de puesta en marcha de la edición electrónica de la revista recayó en su persona, instalando la plataforma Open Journal System para la gestión editorial dentro de los servidores informáticos de nuestra facultad, lo que facilitó, unos años después, su migración al servidor revistas.um.es de nuestra editorial universitaria. Otro apartado donde destacó sobremanera fue en el rigor aplicado a la tarea de revisor. De hecho, raro es el número publicado donde no evaluara la pertinencia de uno o dos manuscritos al menos. También colaboró activamente en la sección de Reseñas, reforzando así su decisiva contribución editorial, gracias a la cual nuestra revista ha alcanzado los actuales niveles de calidad. Sin duda, ha sido uno de los grandes artífices del desarrollo de Anales de Documentación como vehículo de referencia en la comunicación científica del área. Sin su trabajo y dedicación, no estaríamos en este nivel.
Quienes hemos asumido responsabilidades en la revista a lo largo de los años le debemos un profundo agradecimiento por tan valiosa aportación, aunque ese sentimiento se nos antoja ahora como una isla ínfima dentro del océano ante la pérdida de la persona: el compañero de trabajo, el amigo de sus amigos, el esposo, el padre, el hijo y el hermano que nos ha dejado demasiado pronto. Pedro – así lo llamábamos los amigos, colegas y estudiantes – por fortuna pudimos despedirnos de ti y te has marchado sabiendo que, como dice la canción, tú “nunca caminarás solo”, siempre permanecerás acompañándonos en nuestra memoria y en las huellas que dejaste en la revista y en quienes compartimos camino contigo.
La Ciencia Abierta también te va a echar mucho de menos Pedro, y más ahora en estos tiempo donde los avances tecnológicos están abriéndose camino de forma imperativa e imparable.