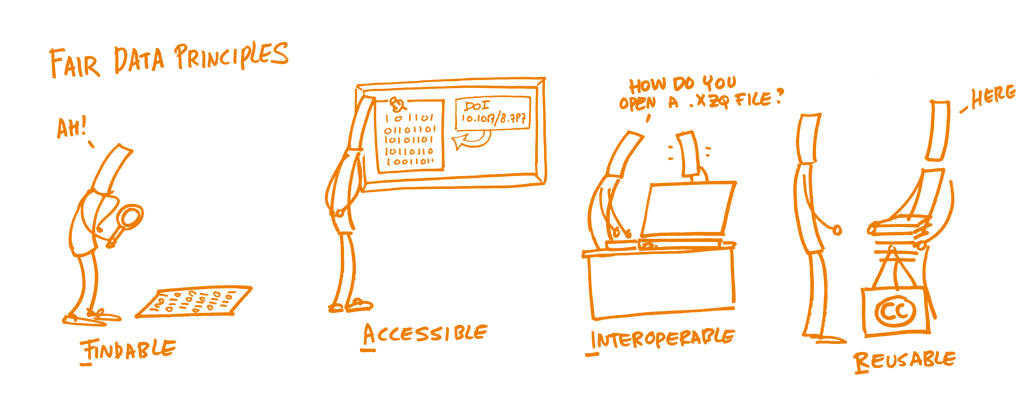
El World Wide Consortium (W3C) publicó en 2017 el documento ‘Data on the Web Best Practices: W3C Recommendation‘ (DWBP), una detallada guía para el diseño, publicación y uso de datos enlazados en la web, con el objeto de promover su accesibilidad, interoperabilidad y reutilización.
Este documento proporciona orientación a los editores de datos en línea sobre cómo representarlos y compartirlos en un formato estándar y accesible. Las prácticas se han desarrollado para fomentar y permitir la expansión continua de la web como medio para el intercambio de datos. El documento menciona el crecimiento en la publicación de datos abiertos por parte de los gobiernos en todo el mundo, la publicación en línea de los datos de investigación, la recolección y análisis de datos de redes sociales, la presencia de importantes colecciones de patrimonio cultural y, en general, el crecimiento sostenido de los datos abiertos en la nube, destacando la necesidad de una comprensión común entre editores y consumidores de datos, junto con la necesidad de mejorar la consistencia en el manejo de los datos.
Estas buenas prácticas cubren diferentes aspectos relacionados con la publicación y el consumo de datos, como son los formatos, el acceso, los identificadores y la gestión de los metadatos. Con el fin de delimitar el alcance y obtener las características necesarias para implementarlas, se recopilaron casos de uso que representan escenarios de cómo se publican habitualmente estos datos y cómo se utilizan. El conjunto de requisitos derivados de esta recopilación se utilizó para guiar el desarrollo de las DWBP, independientes del dominio y la aplicación. Estas recomendaciones pueden ampliarse o complementarse con otros documentos de similar naturaleza. Si bien las DWBP recomiendan usar datos enlazados, también promueven el empleo de otros formatos abiertos como son CSV o json, maximizando más si cabe el potencial de este contexto para establecer vínculos.
| CATEGORÍA | BUENA PRÁCTICA |
| Metadatos Requisito fundamental. Los datos no podrán ser descubiertos o reutilizados por nadie más que el editor si no se proporcionan metadatos suficientes. | BP 1: Proporcionar metadatos BP 2: Proporcionar metadatos descriptivos BP 3: Proporcionar metadatos estructurales |
| Licencias Según el tipo de licencia adoptada por el editor, puede haber más o menos restricciones a la hora de compartir y reutilizar los datos. | BP 4: Proporcionar información sobre la licencia de los datos |
| Procedencia El reto de publicar datos en la web es proporcionar un nivel adecuado de detalle sobre su origen. | BP 5: Proporcionar información sobre la procedencia de los datos |
| Calidad Puede tener un gran impacto en la calidad de las aplicaciones que utilizan un conjunto de datos. | BP 6: Proporcionar información sobre la calidad de los datos |
| Versiones Los conjuntos de datos pueden cambiar con el tiempo. Algunos tienen previsto ese cambio y otros se modifican a medida que las mejoras en la recogida de datos hacen que merezca la pena actualizarlos. | BP 7: Proporcionar un indicador de versión BP 8: Proporcionar el historial de versiones |
| Identificadores El descubrimiento, uso y citación de datos en la web depende fundamentalmente del uso de URI HTTP (o HTTPS): identificadores únicos globales. | BP 9: Utilizar URIs persistentes como identificadores de conjuntos de datos BP 10: Utilizar URIs persistentes como identificadores dentro de conjuntos de datos BP 11: Asignar URIs a versiones y series de conjuntos de datos |
| Formatos El mejor y más flexible mecanismo de acceso del mundo carece de sentido si no se sirven los datos en formatos que permitan su uso y reutilización. | BP 12: Utilizar formatos de datos estandarizados legibles por máquina BP 13: Utilizar representaciones de datos neutras respecto a la localización BP 14: Proporcionar datos en múltiples formatos |
| Vocabularios Se utiliza para clasificar los términos que pueden utilizarse en una aplicación concreta, caracterizar las posibles relaciones y definir las posibles restricciones en su uso. | BP 15: Reutilizar vocabularios, preferentemente estandarizados BP 16: Elegir el nivel adecuado de formalización |
| Acceso a los datos Facilitar el acceso a los datos permite tanto a las personas como a las máquinas aprovechar las ventajas de compartir datos utilizando la infraestructura de la red. | BP 17: Proporcionar descarga masiva BP 18: Proporcionar subconjuntos para conjuntos de datos grandes BP 19: Utilizar negociación de contenidos para servir datos disponibles en múltiples formatos BP 20: Proporcionar acceso en tiempo real BP 21: Proporcionar datos actualizados BP 22: Proporcionar una explicación para datos que no están disponibles BP 23: Hacer datos disponibles a través de una API BP 24: Utilizar estándares web como base de las APIs BP 25: Proporcionar documentación completa para su API BP 26: Evitar cambios que rompan su API |
| Preservación Las medidas deben tomar los editores para indicar que los datos se han eliminado o archivado. | BP 27: Preservar identificadores BP 28: Evaluar la cobertura del conjunto de datos |
| Retroalimentación (‘feedback’) Ayuda a los editores en la mejora de la integridad de los datos, además de fomentar la publicación de nuevos datos. Permite a los consumidores de datos tener voz describiendo experiencias de uso. | BP 29: Recopilar comentarios de los consumidores de datos BP 30: Hacer comentarios disponibles |
| Enriquecimiento Procesos que pueden utilizarse para mejorar, perfeccionar los datos brutos o previamente procesados. Esta idea y otros conceptos similares contribuyen a hacer de los datos un activo valioso para casi cualquier negocio o empresa moderna. | BP 31: Enriquecer datos generando nuevos datos BP 32: Proporcionar presentaciones complementarias |
| Republicación Combinar datos existentes con otros conjuntos de datos, crear aplicaciones web o visualizaciones, o reempaquetar los datos en una nueva forma. | BP 33: Proporcionar comentarios al editor original BP 34: Seguir los términos de la licencia BP 35: Citar la publicación original |
Beneficios e incovenientes de las DWBP
Como podemos ver, se trata de unas pautas que precisan de cierto volumen de trabajo y muchas han de ser aplicadas por personas con mucha experiencia. A continuación, resumimos los beneficios y los (posibles) inconvientes de las mismas.
Beneficios:
- Interoperabilidad: Las prácticas están diseñadas para asegurar que los datos publicados sean comprensibles y accesibles para una amplia variedad de aplicaciones y sistemas. Esto facilita la integración y el intercambio de datos entre organizaciones y plataformas.
- Reutilización: Si se siguen las buenas prácticas, los datos se estructuran coherentemente y se proporcionan metadatos claros. Esto facilita la reutilización de los datos por parte de otros usuarios y organizaciones para crear nuevas aplicaciones, servicios o análisis. Esto fomenta la innovación y la creación de valor.
- Calidad de los datos: Las buenas prácticas promueven la calidad de los datos al definir estándares para la representación y la semántica de los datos. Esto reduce los errores y las ambigüedades en los datos publicados, mejorando la confiabilidad y la precisión de la información.
- Accesibilidad: Un seguimiento de las buenas prácticas asegura que los datos estén disponibles y sean accesibles para un público amplio, incluyendo personas con discapacidades. Esto promueve la inclusión y garantiza que los datos estén disponibles para todos los usuarios, independientemente de sus necesidades.
- Indexación y búsqueda: Los motores de búsqueda comprenden mejor e indexan más eficazmente los datos que siguen las DWBP. Esto mejora su encontrabilidad, aumentando la visibilidad de los datos en los resultados, lo que aumenta su alcance y utilidad.
- Transparencia: Publicar datos según estándares abiertos y transparentes, se promueve la transparencia y la rendición de cuentas. Esto es especialmente importante en los datos de las administraciones públicas y también en datos científicos, donde la accesibilidad a los conjuntos de datos es esencial para la toma de decisiones informadas y la supervisión.
- Facilita la colaboración: Estas buenas prácticas fomentan la colaboración entre organizaciones y comunidades al proporcionar un marco común para compartir datos. Esto es especialmente útil en proyectos de colaboración donde múltiples partes necesitan compartir y trabajar con datos de manera eficiente.
Posibles inconvenientes
- Coste: Implementar las DWBP puede requerir inversiones significativas en recursos humanos y tecnológicos, lo que es un problema para organizaciones con presupuestos limitados.
- Complejidad: Algunas de las mejores prácticas del W3C resultan técnicamente complejas de implementar, especialmente para personas u organizaciones sin experiencia previa en estándares web y tecnologías relacionadas.
- Cumplimiento: Asegurarse de cumplir con todas las directrices y recomendaciones puede ser un desafío, y el incumplimiento podría afectar la efectividad de la publicación de datos.
- Adopción: No todas las organizaciones y comunidades pueden estar dispuestas o capacitadas para adoptar estas prácticas de inmediato. Esto puede limitar la interoperabilidad y la reutilización de datos.
- Seguridad y privacidad: La publicación de datos ha de hacerse con precaución para evitar la divulgación de información sensible o privada. El cumplimiento de las normativas de protección de datos es esencial y requiere un esfuerzo adicional.
- Actualización continua: Mantener los datos actualizados y en conformidad con las buenas prácticas puede ser un verdadero desafío a largo plazo. Esto va a precisar de dedicación y recursos continuos.

En resumen, publicar datos siguiendo las Data Web Best Practices del W3C ofrece numerosos beneficios en términos de interoperabilidad, reutilización de datos, calidad de datos, accesibilidad y transparencia. Sin embargo, también conlleva inconvenientes relacionados con el costo, la complejidad, el cumplimiento, la adopción, la seguridad y la privacidad, así como la necesidad de mantener los datos actualizados. Seguir estas mejores prácticas va a depender de los objetivos y recursos de la organización y de su compromiso con la calidad y la accesibilidad de los datos a publicar.
En otras entradas seguiremos hablando de buenas prácticas y conjuntos de datos, algo preciso para llegar a la Ciencia Abierta.