Actualizo una entrada de noviembre en 2019 sobre el «Contrato para la Web» que puso en marcha el inventor de todo esto, Sir Tim Berners-Lee, para intentar asegurar que internet debe seguir siendo un bien público para toda la sociedad.

«La web se diseñó para unir a la gente y hacer que el conocimiento fuese accesible para todos y todas. Ha cambiado el mundo para bien y ha mejorado la vida de miles de millones de personas. Sin embargo, todavía hay muchas personas que no pueden acceder a sus ventajas y muchas otras para las que la Web supone un coste demasiado elevado.
Todos tenemos un papel que cumplir a la hora de salvaguardar el futuro de la Web. Los representantes de más de 80 organizaciones redactaron el Contrato para la Web en nombre de gobiernos, empresas y la sociedad civil. En él se establecen los compromisos que deben guiar las políticas digitales. Con el fin de alcanzar los objetivos del Contrato, los gobiernos, las empresas, la sociedad civil y las personas deben comprometerse con el desarrollo sostenido de dichas políticas, así como con la defensa y la implementación de este texto».
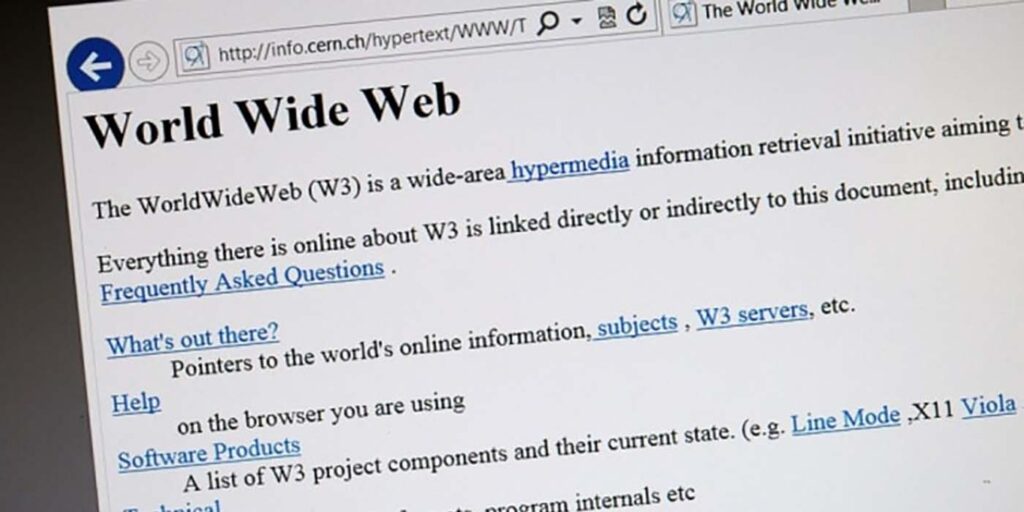
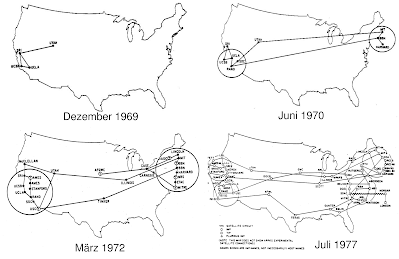
Así presentaba en el año 2019 Sir Tim Berners-Lee, el inventor de la web, su iniciativa llamada «Contrato para la Web«. El objeto de la misma era garantizar que todos tenemos acceso a ella, no solo las personas que viven en países donde el nivel de vida lo permitiera y el gobierno sea democrático. La idea de Berners-Lee iba en la línea de conseguir el verdadero acceso universal a «su criatura», la que propuso casi de escondidas a sus jefes del CERN hace más de 30 años.
Este contrato se estructuraba en 9 principios básicos que presentamos de forma resumida:
- Asegurarse de que todo el mundo pueda conectarse a internet para que cualquier persona, independientemente de quién sea o dónde viva, pueda participar de forma activa en la red.
- Hacer que la totalidad de internet esté disponible en todo momento para que a nadie se le niegue el derecho a disfrutar de un acceso completo a la red.
- Respetar y proteger los derechos básicos de las personas sobre sus datos y su privacidad en la red para que todo el mundo pueda usar Internet libremente de forma segura y sin miedo.
- Hacer que el acceso a internet sea asequible y accesible para todo el mundo para que nadie quede excluido del uso y el desarrollo de la web.
- Respetar y proteger la privacidad y los datos personales, con el fin de generar confianza en la red para que las personas tengan el control sobre sus vidas en Internet y que cuenten con opciones claras y relevantes en lo relativo a sus datos y su privacidad.
- Desarrollar tecnologías que promuevan lo mejor de la humanidad y contribuyan a mitigar lo peor para que la web sea realmente un bien público en donde prevalezca el interés de las personas.
- Crear y colaborar en la web para que la web tenga un contenido rico y relevante para todos.
- Construir comunidades sólidas que respeten el discurso civil y la dignidad humana para que todo el mundo se sienta seguro y bienvenido en la red.
- Luchar por la web para que siga siendo abierta y un recurso público global para las personas de todo el mundo, ahora y en el futuro.
Estos principios afectan («reclaman» más bien) a gobiernos, empresas y ciudadanos. Están dirigidos a gran parte (a lo mejor a toda) de la sociedad actual. Asegurar que la red tenga infraestructura suficiente, que el acceso sea lo más barato posible, que se respeten los derechos de los usuarios y que su uso esté dirigido a mejorar a las personas, son causas por las que vale la pena postularse, más allá de rellenar el formulario de adhesión y hacer clic con el dedo en la pantalla del teléfono.
Actualización a fecha de 2026.

Al momento de su lanzamiento, gobiernos como Francia y Alemania se sumaron a la iniciativa. El gobierno alemán anunció su apoyo a la iniciativa en noviembre de 2018, destacando internet como un «bien público» y un derecho fundamental que debe ser protegido, asegurando el acceso para todos y respetando la privacidad. El gobierno francés también se adhirió a la iniciativa en términos similares. Además, la Unión Europea se ha alineado estrechamente con los principios básicos dictados por Berners-Lee, al igual que los esfuerzos conjuntos de Estados Unidos y otros 60 países firmantes de la «Declaración para el Futuro de Internet«, que busca un internet abierto, seguro y libre. Países como Ghana y Brasil han tenido intervenciones directas apoyadas por la Web Foundation para mejorar la asequibilidad y los derechos digitales.
En el caso brasileño, apoyó activamente el desarrollo y aprobación del Marco Civil da Internet en Brasil, considerado el primer «proyecto de ley de derechos» de internet en el mundo. Esta legislación consagraba derechos fundamentales como la neutralidad de la red, la privacidad y la libertad de expresión. En Ghana, la fundación trabajó para abordar la brecha digital, particularmente la brecha de género, a través de la red Women’s Rights Online (WRO). Esto incluye la promoción de políticas de TIC que sean sensibles al género, fomentando el acceso a internet asequible y garantizando los derechos digitales de las mujeres.
Las políticas públicas influenciadas por el contrato se centran en los tres pilares de gobierno del documento:
- 1. Asegurar la conectividad (acceso): Políticas destinadas a reducir la brecha digital y garantizar que todo el mundo pueda conectarse a internet, haciendo que sea asequible y accesible.
- 2. Mantener la red abierta (neutralidad y disponibilidad): Normativas que prohíben el cierre o la censura total de internet por parte de los gobiernos.
- 3. Respetar la privacidad y datos (gobernanza): Políticas alineadas con el cumplimiento de derechos de datos, similares al RGPD (Reglamento General de Protección de Datos) en la UE.
Principales aliados tecnológicos:
Más de 150 organizaciones respaldan la iniciativa, incluyendo grandes tecnológicas como Google, Facebook (Meta), GitHub, Reddit y DuckDuckGo, que han ajustado sus políticas de producto a estos principios.
Para finalizar, queremos recordar que el contrato no es solo una aspiración, es una verdadera «hoja de ruta» para políticas concretas para asegurar que internet siga siendo una herramienta para el bien público.