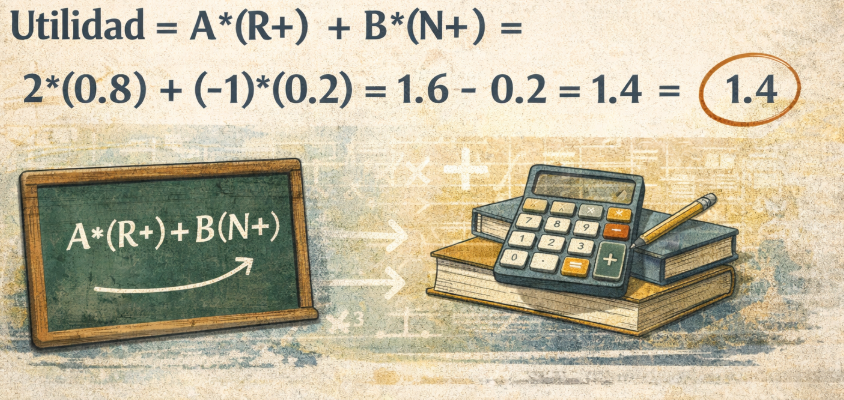Seguimos intentando convencernos de las ventajas del uso de los metadatos. El otro día, buscando en Google por «metadatos» y «usabilidad» me encontré un trabajo con la siguiente frase al comienzo:
Supongo que algunos ya saben que el autor de esta frase es el profesor e investigador Ricardo Baeza-Yates en el artículo titulado «Ubicuidad y Usabilidad en la Web» escrito en 2002. El mismo introduce la idea de que un sitio web “bueno” no se define únicamente por su estética, sino por una secuencia de condiciones necesarias para que el usuario llegue a usarlo y, sobre todo, vuelva a visitarlo. El autor parte de un princicio claro: la web crece a un ritmo tan acelerado (y con tanta renovación de páginas) que es imposible pensar que todos los sitios van a ser diseñados por especialistas en interfaces. De ahí se desprenden tres salidas: (1) facilitar que se diseñen sitios razonables sin ser experto; (2) formar a más gente en diseño o (3) resignarse a un ecosistema web difícil de usar. Mediante la analogía con una tienda física, Baeza-Yates explica que la desorganización, la mala ayuda y la dificultad para encontrar lo que se busca llevan al abandono del sitio, algo frecuente en cualquier ámbito, no solo en comercio electrónico.
El éxito de una página depende de su facilidad de uso y de localización
Sobre esa base, el artículo articula dos conceptos clave en la web: ubicuidad y usabilidad. Primero, un sitio debe ser “ubicuo”: poder ser encontrado y accedido. La ubicuidad se descompone en buscabilidad (que el sitio sea localizable, especialmente a través de buscadores) y visibilidad (que el sitio pueda verse y cargue adecuadamente en condiciones técnicas diversas). Esto implica acciones concretas: asegurar que los buscadores puedan rastrear el sitio (registro, enlaces entrantes, evitar barreras como Flash, mapas de imagen, ‘frames’ o JavaScript mal usado), cuidar el vocabulario de la página principal para que coincida con los términos de los usuarios, y mejorar la posición con enlaces y metadatos (con cautela por el “spam” de metadatos). La visibilidad, por su parte, exige ligereza (tamaños moderados), compatibilidad con distintos navegadores y sistemas, y atención a la accesibilidad (WAI), recordando que los robots de búsqueda “son ciegos” y que los enlaces textuales ayudan a usuarios y buscadores.
Después, una vez que el sitio se encuentra y se ve, entra la usabilidad, definida (Norma ISO 9241-11) como efectividad, eficiencia y satisfacción en un contexto de uso. Se revisan atributos clásicos (aprendizaje, velocidad, errores, retención, satisfacción) y otros complementarios (control, apoyo a habilidades, privacidad). Finalmente, se expone la ingeniería de usabilidad y la evaluación como núcleo del proceso: inspecciones, pruebas con usuarios, pensar en voz alta, evaluaciones heurísticas, caminatas cognitivas y encuestas. El texto culmina con heurísticas y recomendaciones prácticas (consistencia, prevención de errores, diseño minimalista, rapidez, compatibilidad, diseño para diversidad, escritura concisa), subrayando que la verdadera meta es la fidelidad del usuario: que encuentre, use, se “seduzca” y regrese.
Cuenta Donna K. Harman en el capítulo séptimo de ‘TREC: Experiment and Evaluation in Information Retrieval‘ que a partir de la conferencia TREC-3 comenzaron a probarse distintos sistemas de recuperación de información implementados en colecciones de documentos multilingües. Hasta ese momento, como es fácil suponer solo se había empleado el Inglés.
En esa conferencia, cuatro grupos trabajaron con una colección de 58.000 documentos procedentes de un periódico de Monterrey llamado El Norte (aproximadamente 200 megabtytes de tamaño). Los grupos usaron búsquedas simples y analizaron el comportamiento del sistema con un total de 25 preguntas. Algunos de estos grupos (de las universidades de Cornell y Amherst -Massachusetts), trasladaron sus sistemas directamente, con la única salvedad de los ficheros de palabras vacías que ahora iban a ser términos en español. Los otros dos grupos (Dublin -«la del Core»- y Michigan) usaron desarrollos adaptados al nuevo idioma, modificando la primera de ellas el original algoritmo de lematización (‘stemming‘) propuesto por Porter.
El principal resultado de este experimento fue la facilidad de portabilidad de las aplicaciones y técnicas de recuperación de información a textos escritos en otro idioma, el nuestro en este caso. En el informe de la Universidad de Cornell se decía que bastaban unas pocas horas de trabajo para garantizar la misma efectividad de los sistemas. Estas conclusiones iniciales fueron refrendadas posteriormente en las conferencias TREC-4 y TREC-5. La inmortal lengua de Miguel de Cervantes está al mismo nivel que la de Shakespeare, por tanto.
Esta medida esencialmente asume que la presencia de documentos relevantes en la respuesta de un sistema de recuperación de información a una determinada pregunta debe tomarse como un rédito a favor del sistema, al mismo tiempo que los documentos no relevantes deben considerarse como un débito. Por lo tanto, esta medida establece su valor favoreciendo el acierto y penalizando al mismo tiempo el desacierto. Su cálculo es muy intuitivo, se multiplica por un factor (A) el porcentaje de documentos relevantes (R+) y a este producto se le suma el producto de un segundo factor (B) por el total de documentos no relevantes (N+). Como el segundo factor es de penalización su valor es negativo, por lo tanto más que sumar se resta. Así, si en una búsqueda determinada, nuestro buscador devuelve un 80% de documentos relevantes (por tanto, un 20% de no relevantes), los valores de R+ y N+ serían 0.8 y 0.2 respectivamente.
Ahora queda por establecer los valores de los factores A y B, que son introducidos por el evaluador según estime oportuno. En las conferencias TRECs 9-11 se optó por utilizar A=2 y B=-1, asumiendo que la posibilidad de recuperar un documento relevante era del 66% y de encontrar un documento no relevante era del 33%, de ahí que el valor absoluto de A sea el doble que el de B. Con estos parámetros, nuestra búsqueda ejemplo tendría el siguiente valor de utilidad lineal que podemos vers de forma esquemática en la figura siguiente:
Cálculo de la utilidad lineal ilustrado.
Esta utilidad indica que la búsqueda es buena, algo que así parecía al tener un 80% de documentos relevantes, cuya influencia en la medida refuerza esta fórmula. Lo cierto es que quizá (solo quizá) a veces nos complicarnos mucho la cabeza a la hora de establecer una medida de evaluación de la recuperación de información. De hecho, en TREC-8 los autores experimentaron con una ‘utilidad no lineal’ que resultó difícil de interpretar y fue deshechada.
El trabajo explica de forma divulgativa y rigurosa el fundamento matemático que subyace al éxito del buscador Google, centrado en su algoritmo de alineamiento PageRank, cuyo núcleo conceptual se basa en el álgebra lineal. El autor parte de la constatación de que Google se consolidó rápidamente como buscador dominante no solo por la cantidad de información indexada, sino, sobre todo, por la calidad del ordenamiento de los resultados de búsqueda, que difiere de enfoques basados únicamente en la coincidencia de términos.
El artículo concibe a la web como un grafo dirigido, en el que las páginas son los nodos y los enlaces hipervinculados representan aristas. Desde esta perspectiva, la relevancia de una página no depende solo de su contenido, sino del número y la calidad de las páginas que enlazan hacia ella. Esta idea se formaliza mediante una matriz que representa las probabilidades de transición entre páginas, interpretando la navegación de un usuario como un proceso estocástico. El valor de PageRank de una página se define entonces como la probabilidad de que un “navegante aleatorio” se encuentre en ella tras un número elevado de pasos.
Fórmula de Pagerank ilustrada
En esencia, el algoritmo se basa en un cálculo que permite identificar qué páginas son más importantes dentro de toda la red, a partir de la estructura de enlaces que las conectan entre sí., lo que conecta directamente el problema con conceptos clásicos del álgebra lineal, como matrices, autovalores, autovectores y convergencia. El autor explica cómo la introducción de un factor de amortiguación garantiza la existencia y unicidad de la solución, evitando problemas como ciclos cerrados o componentes desconectadas del grafo.
Finalmente, el trabajo subraya el valor didáctico del PageRank como ejemplo de aplicación real del álgebra lineal, mostrando cómo herramientas matemáticas abstractas pueden resolver problemas prácticos de gran escala. Más allá de Google, el artículo pone de relieve la importancia de los modelos matemáticos en la recuperación de información y en el análisis de redes, anticipando su relevancia en ámbitos como la ciencia de datos, la web semántica y los sistemas de recomendación.
Esta mañana recibía el agradable comentario que os acompaño:
«Hola, javima: Un grupo de amigas estamos buscando información sobre diseño paginas web cuando encontramos tu blog. Tu título, Textffiles: memoria de Internet., nos ha gustado y lo hemos comentado. Estamos tratando de escribir algo relacionado con diseño paginas web para un proyecto de internet. Muchas gracias por permitirnos aprender de ti con tu excelente blog.»
Desde hace unos meses vengo barruntando una idea sobre los sitios web que cada vez se afianza más, y no es otra que si queremos tener unos sitios web visitados y, que por tanto cumplan con su cometido (es decir, que sean «eficaces» (como decían mis amigos Juanki y Juan en un curso que impartieron hace unos meses). Pero, lo que está claro es que, además de cuidar los aspectos estéticos y la usabilidad, lo verdaderamente importante de un sitio web es, casi como diría Perogrullo si de esto supiera algo, su contenido.
Repito, cada día estoy más convencido, pero hoy un poquito más, tras leer el post ‘Search Engines and King Content‘ publicado hoy por Tony Wright en searchenginewatch.com. Siguiendo el enlace del título podemos leerlo.
Pero mucho antes de esto, en el año 1996, fue Bill Gates quien introdujo esta idea en un post en el que hablaba sobre la siguiente revolución, la de la información. Acertó de pleno el cofundador de Microsoft.
Texto original (fuente: Microsoft).
Content is King by Bill Gates (1/3/1996)
El contenido es donde espero que se genere la mayor parte del dinero real en Internet, tal como ocurrió con la radiodifusión.
La revolución televisiva que comenzó hace medio siglo dio origen a varias industrias, incluyendo la fabricación de televisores, pero los verdaderos ganadores a largo plazo fueron aquellos que utilizaron el medio para ofrecer información y entretenimiento.
Cuando se trata de una red interactiva como Internet, la definición de “contenido” se vuelve muy amplia. Por ejemplo, el software es una forma de contenido —una extremadamente importante— y para Microsoft seguirá siendo, por mucho, la más relevante.
Pero las grandes oportunidades para la mayoría de las empresas están en proporcionar información o entretenimiento. Ninguna empresa es demasiado pequeña para participar.
Una de las cosas más emocionantes de Internet es que cualquier persona con una PC y un módem puede publicar el contenido que sea capaz de crear. En cierto sentido, Internet es el equivalente multimedia de la fotocopiadora. Permite duplicar material a bajo costo, sin importar el tamaño de la audiencia.
Internet también permite distribuir información a nivel mundial con un costo marginal prácticamente nulo para el editor. Las oportunidades son extraordinarias, y muchas empresas ya están planeando crear contenido para Internet.
Por ejemplo, la cadena de televisión NBC y Microsoft acordaron recientemente ingresar juntas al negocio de noticias interactivas. Nuestras compañías serán copropietarias de una cadena de noticias por cable, MSNBC, y de un servicio de noticias interactivo en Internet. NBC mantendrá el control editorial de la empresa conjunta.
Espero que las sociedades vean una intensa competencia —y abundante fracaso así como éxitos— en todas las categorías de contenido popular: no solo software y noticias, sino también juegos, entretenimiento, programación deportiva, directorios, anuncios clasificados y comunidades en línea dedicadas a intereses importantes.
Las revistas impresas tienen lectores que comparten intereses comunes. Es fácil imaginar a estas comunidades siendo atendidas mediante ediciones electrónicas en línea.
Pero para tener éxito en línea, una revista no puede simplemente trasladar su contenido impreso al entorno digital. El contenido impreso carece de la profundidad o interactividad necesarias para compensar las limitaciones del medio en línea.
Si se espera que las personas enciendan un ordenador para leer en pantalla, deben ser recompensadas con información profunda y extremadamente actualizada que puedan explorar libremente. Necesitan acceso a audio, y posiblemente a video. Necesitan una oportunidad de participación personal que vaya mucho más allá de las cartas al editor que ofrecen las revistas impresas.
Una pregunta que muchos se hacen es si la misma empresa que sirve a un grupo de interés mediante medios impresos podrá tener éxito también en línea. Incluso el futuro mismo de ciertas revistas impresas está siendo puesto en duda por Internet.
Por ejemplo, Internet ya está revolucionando el intercambio de información científica especializada. Las revistas científicas impresas tienden a tener pequeñas tiradas, lo que las hace costosas. Las bibliotecas universitarias representan gran parte del mercado. Ha sido un modo incómodo, lento y costoso de distribuir información a una audiencia especializada, pero no había alternativa.
Ahora, algunos investigadores están empezando a usar Internet para publicar sus hallazgos científicos. Esta práctica pone en entredicho el futuro de algunas revistas impresas prestigiosas.
Con el tiempo, la amplitud de la información disponible en Internet será enorme, lo que la hará muy atractiva. Aunque el “ambiente de fiebre del oro” de hoy se limita principalmente a Estados Unidos, espero que se extienda por todo el mundo a medida que disminuyan los costos de comunicación y aparezca contenido localizado en diversos países.
Para que Internet prospere, los proveedores de contenido deben ser remunerados por su trabajo. Las perspectivas a largo plazo son buenas, pero espero muchas decepciones a corto plazo, mientras las empresas de contenido luchan por obtener ingresos mediante publicidad o suscripciones. Aún no funciona, y puede que no lo haga durante un tiempo.
Hasta ahora, la mayoría del dinero y esfuerzo invertido en publicación interactiva es poco más que un acto de amor o una forma de promocionar productos del mundo no digital. A menudo, estos esfuerzos se basan en la creencia de que, con el tiempo, alguien descubrirá cómo generar ingresos.
A largo plazo, la publicidad es prometedora. Una ventaja de la publicidad interactiva es que un mensaje inicial solo necesita captar la atención, no comunicar mucha información. El usuario puede hacer clic en el anuncio para obtener más detalles, y el anunciante puede medir si la gente lo hace.
Pero hoy en día, los ingresos totales por publicidad o suscripciones en Internet son casi nulos —tal vez entre 20 y 30 millones de dólares en total. Los anunciantes siempre son algo reacios ante un nuevo medio, y sin duda Internet es nuevo y diferente.
Parte de esa reticencia puede estar justificada, porque muchos usuarios de Internet no están muy entusiasmados con ver anuncios. Una razón es que muchos anuncios contienen imágenes grandes que tardan mucho en cargarse con una conexión telefónica. Un anuncio en una revista impresa también ocupa espacio, pero el lector puede pasar la página rápidamente.
A medida que las conexiones a Internet se vuelvan más rápidas, la molestia de esperar a que se cargue un anuncio disminuirá y eventualmente desaparecerá. Pero eso tomará algunos años.
Algunas empresas de contenido están experimentando con suscripciones, a menudo ofreciendo parte del contenido gratis. Pero es complicado, porque en cuanto una comunidad electrónica comienza a cobrar, la cantidad de visitantes al sitio cae drásticamente, lo que reduce el valor para los anunciantes.
Una razón importante por la que cobrar por contenido no funciona muy bien todavía es que no es práctico cobrar pequeñas cantidades. El costo y la molestia de las transacciones electrónicas hacen poco viable cobrar menos que una suscripción considerable.
Pero dentro de un año estarán disponibles mecanismos que permitirán a los proveedores de contenido cobrar solo un centavo o unos pocos por su información. Si decides visitar una página que cuesta cinco centavos, no tendrás que escribir un cheque ni recibir una factura por esa cantidad. Simplemente harás clic sabiendo que se te cobrará en forma agregada.
Esta tecnología liberará a los editores para que cobren pequeñas sumas con la esperanza de atraer grandes audiencias.
Los que tengan éxito impulsarán a Internet como un mercado de ideas, experiencias y productos —un mercado de contenido.
En algunas partes de esta web hablamos de Gerad Salton y de «su Modelo del Espacio Vectorialque implementan la mayoría de los motores de búsqueda lo implementan como estructura de datos y que el alineamiento suele realizarse en función del parecido (o similitud) de la pregunta con los documentos almacenados. Viniendo hacia el trabajo me he parado a pensar que igual muchos no saben cómo funciona realmente este modelo y que no sería nada malo dedicarle una pequeña serie de posts para explicarlo. Vamos a ello.
La idea básica de este modelo reside en la construcción de una matriz (podría llamarse tabla) de términos y documentos, donde las filas fueran estos últimos y las columnas correspondieran a los términos incluidos en ellos. Así, las filas de esta matriz (que en términos algebraicos se denominan vectores) serían equivalentes a los documentos que se expresarían en función de las apariciones (frecuencia) de cada término. De esta manera, un documento podría expresarse de la manera d1=(1, 2, 0, 0, 0, … … …, 1, 3) siendo cada uno de estos valores el número de veces que aparece cada término en el documento. La longitud del vector de documentos sería igual al total de términos de la matriz (el número de columnas).
De esta manera, un conjunto de m documentos se almacenaría en una matriz de m filas por n columnas, siendo n el total de términos almacenamos en ese conjunto de documentos. La segunda idea asociada a este modelo es calcular la similitud entre la pregunta (que se convertiría en el vector pregunta, expresado en función de la aparición de los n términos en la expresión de búsqueda) y los m vectores de documentos almacenados. Los más similares serían aquellos que deberían colocarse en los primeros lugares de la respuesta.
¿Cómo se calcula esta similitud? Disponemos de varias fórmulas que nos permiten realizar este cálculo, la más conocida es la Función del Coseno, que equivale a calcular el producto escalar de dos vectores de documentos (A y B) y dividirlo por la raíz cuadrada del sumatorio de los componentes del vector A multiplicada por la raíz cuadrada del sumatorio de los componentes del vector B.
No hay que asustarse a la hora de oir hablar de «producto escalar de dos vectores», ya que se calcula multiplicando componente a componente y sumando los productos. Así, si disponemos de los vectores de documentos A (1, 0, 1, 0, 1, 0) y B (1, 0, 1, 1, 0, 0) su valor de similitud según la función del Coseno se calculará tal como podemos ver en la siguiente tabla:
De esta manera tan sencilla se calcula este valor de similitud. Como es obvio, si no hay coincidencia alguna entre los componentes, la similitud de los vectores será cero ya que el producto escalar será cero (circunstancia muy frecuente en la realidad ya que los vectores llegan a tener miles de componentes y se da el caso de la no coincidencia con mayor frecuencia de lo que cabría pensar). También es lógico imaginar que la similitud máxima sólo se da cuando todos los componentes de los vectores son iguales, en este caso la función del coseno obtiene su máximo valor, la unidad. Lo normal es que los términos de las columnas de la matriz hayan sido filtrados (supresión de palabras vacías) y que en lugar de corresponder a palabras, equivalgan a su raíz ‘stemmed’ (agrupamiento de términos en función de su base léxica común, por ejemplo: economista, económico, economía, económicamente, etc.). Generalmente las tildes y las mayúsculas/minúsculas son ignorados. Esto se hace para que las dimensiones de la matriz, de por sí considerablemente grandes no alcancen valores imposibles de gestionar. No obstante podemos encontrar excepciones a la regla general, tal como parece ser el caso de Yahoo!, que no ignora las palabras vacías.
Para finalizar, la del coseno no es la única función de similitud. Existen otras, entre las que destacan las de Dice y Jaccar, pero que pueden resultar algo más engorrosas no sólo de calcular sino más bien de interpretar y que por tanto son menos aplicadas en Recuperación de Información