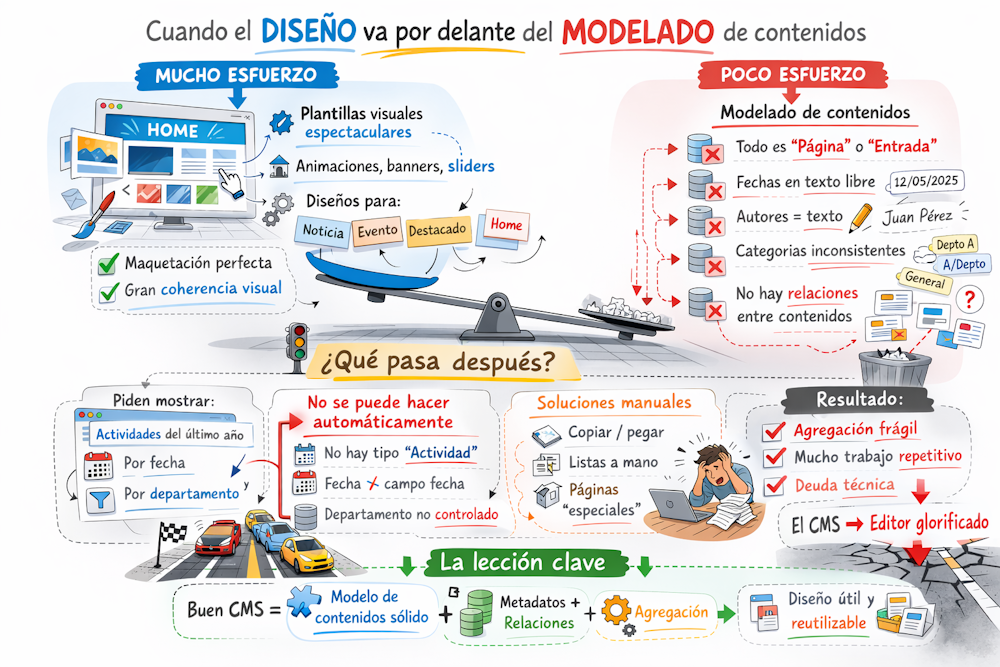
¿Por qué GEO?
Hace unos días escuché a unas de las personas que se presenta a las elecciones al rectorado de la Universidad de Murcia comentar en una entrevista en un podcast que quizá estábamos escribiendo páginas web bajo el paradigma equivocado porque son muchos los usuarios que emplean las gramáticas generativas IA tipo chatGPT, Gemini, Claude, Perplexity, etc. para recuperar información en lugar de los motores de búsqueda tradicionales y podemos preparar nuestras entradas de forma optimizada para esta nueva tecnología, avanzando desde el SEO hasta el GEO (siglas de ‘Generative Engine Optimization‘).

Desde entonces vengo preguntándome sobre esta cuestión y voy a decicar algunas entradas (redactadas en el formato «tradicional» de este blog, pero intentando tomar nota de algunas de las recomendaciones que he encontrado al respecto) a esta cuestión.
Claves del cambio de paradigma
Sabemos que los buscadores tradicional devuelven listas de enlaces a partir de palabras clave y la correspondencia entre esas palabras y el contenido de las páginas web. Una gramática generativa LLM devuelve respuestas construidas a partir de fragmentos de información. Esta diferencia es substancial y deja claro que estamos comparando tecnologías diferentes. Ahora, sin dejar de conferir importancia a la entrada en sí misma como unidad, para las gramáticas generativas resulta más trascendente que el contenido pueda ser reutilizado como una unidad de conocimiento.
1. Credibilidad: si no es verificable, no sirve.
Los modelos generativos priorizan contenidos en los que se puede “confiar”, prefieren textos con fuentes identificables, contenidos con datos concretos y de autoría clara, como se comprueba en esta búsqueda en el modo IA de Google:
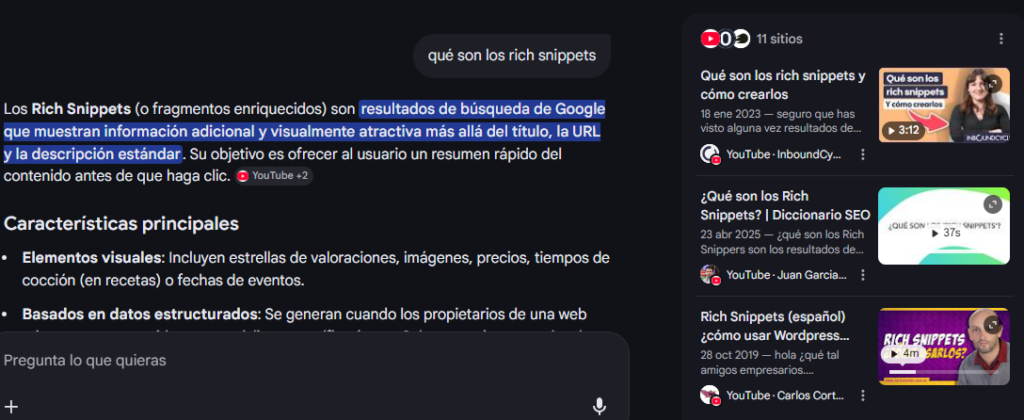
Además de elaborar un resumen para responder a la cuestión, muestra en la parte derecha de la pantalla las fuentes de información que le sirven de soporte. Entre los criterios que necesitamos los autores para ganarnos esa «confianza» destacan:
- citar informes, artículos o datasets
- incluir cifras, porcentajes o resultados medibles
- indicar quién escribe y cuándo
Está claro que cuanto más verificable sea nuestro contenido, más probable es que sea reutilizado. Esto es algo habitual en el mundo científico al escribir un artículo, el mismo debe apoyarse en fuentes de autoridad contrastada que terminan confiriéndole a nuestro trabajo la calidad suficiente para ganar calidad en el seno de la comunidad científica. Esto no es frecuente en la web actual. Por cierto, he usado viñetas en lugar de escribir en un párrafo los criterios «de confianza» para las gramáticas LLM, lo he hecho porque esa forma de exponer el contenido también les parece interesante.
2. Estructura: escribir pensando en fragmentos, no en páginas.
Las gramáticas generativas no “leen artículos”, trabajan con fragmentos (‘chunks‘). Los autores podemos, fácilmente, ayudar a ello usando los encabezados (H1, H2, H3, …) de una forma clara y consistente (de hecho, cualquiera que siga este blog verá que hay más encabezados que de costumbre, antes no hacía tanto uso de ellos). Dividir el contenido en bloques pequeños y evitar referirnos a esos bloques (párrafos) con expresiones ambiguas del estilo de “esto último permite” o “lo anterior indica” servirá para aumentar el interés de esas gramáticas hacia nuestra entrada web, esto no contradice para nada lo que hemos venido haciendo hasta ahora. La novedad fundamental reside en estructurar en formato pregunta–respuesta estos fragmentos de información, por ejemplo:

Este tipo de bloques de contenido encaja perfectamente con cómo funcionan los sistemas RAG (Retrieval-Augmented Generation), técnica que mejora la precisión de los modelos LLM en la consulta de fuentes de datos externos.
3. Claridad: menos retórica, más información.
Para un lector humano, cierto grado de estilo es positivo, aunque siempre se ha comentado que la web no es el lugar para perífrasis y circunloquios. Para una gramática generativa LLM lo importante es encontrar contenidos con:
- frases claras
- conceptos explícitos
- poca ambigüedad
Asím funciona mejor la frase «Un eclipse solar ocurre cuando la Luna bloquea la luz del Sol desde la Tierra” que el texto «Este fenómeno sucede cuando se alinean ciertos cuerpos celestes”. Redactar sencillo genera contenido de fácil comprensión y mayor reutilización. La clave es la densidad informativa (cuánta información útil y concreta hay en una frase o texto en relación con su longitud).
4. Metadatos para ayudar a las máquinas a entender el contenido.
Si bien no es obligatorio, añadir metadatos estructurados, lo cierto es que ayuda bastante. Aquí entramos en el territorio de Schema.org y de los datos estructurados que sirven para indicar (entre otras cosas):
- tipo de contenido (artículo, dataset, etc.)
- autor
- fecha
- tema
Este enriquecimiento de los sitios web con microdatos reduce la ambigüedad del texto y mejora la interoperabilidad con sistemas externos. En este caso, esto es positivo tanto para las gramáticas generativas como para la recuperación de información tradicional.
5. Pensar en RAG: cómo “leen” realmente estos sistemas.
Muchos sistemas actuales combinan modelos de lenguaje con recuperación de información RAG. Esto implica:
- el contenido se fragmenta
- el contenido se convierte en vectores (‘embeddings‘)
- del contenido se van a recuperar los fragmentos más relevantes
- el modelo genera la respuesta
Lo cierto es que los autores no podemos controlar este proceso, pero sí facilitarlo por medio de:
- bloques de contenido de tamaño medio (ni demasiado largos ni demasiado cortos)
- repetir ligeramente conceptos clave (sin forzar)
- responder preguntas que el usuario realmente haría
Lo cierto es que las dos primeras recomendaciones también son válidas para la recuperación de información tradicional, es la tercera (que ya hemos adelantado) la que representa una novedad: escribir pensando en preguntas concretas.
6. Qué ya no funciona (o funciona peor)
Algunas prácticas del SEO clásico pierden sentido aquí:
- keyword stuffing (uso excesivo de palabras clave) → irrelevante o incluso perjudicial
- textos largos sin estructura → difíciles de reutilizar
- contenido genérico sin datos → baja probabilidad de uso
Tanto el exceso de palabras clave como la desestructuración de los textos sabemos desde hace tiempo que estaba penalizado en la recuperación de información clásica. En el contexto GEO podemos considerar su abolición como una premisa. En GEO, más no es mejor: mejor es mejor.
Resumiendo …
Todo esto se puede resumir así en una frase corta: «No escribas páginas. Diseña unidades de conocimiento«. Para ello, debemos seguir, como mínimo, esta serie de pasos:
- Hacer el contenido verificable (fuentes, datos, autoría).Q
- Estructurar el texto en bloques claros (mejor si son preguntas y respuestas).
- Escribir de forma explícita y sin ambigüedades.
- Facilitar la fragmentación del contenido (‘chunking’).
La optimización del contenido para las gramáticas generativas no sustituye completamente al SEO, lo que hace es añadir una nueva capa.
Para finalizar, le he pedido a Google Notebook LLM que prepare un pequeño vídeo para mostrar la transición del SEo al nuevo paradigma GEO a `partir de algunas de las fuentes que hemos empleado para preparar esta entrada. Creo que ha quedado interesante.