Uno de los experimentos que llevé a cabo cuando mi tesis doctoral fue intentar determinar la similitud en la respuesta de los motores de búsqueda. A partir de los 30 primeros documentos devueltos por seis motores a 30 preguntas, determinamos que la similitud de la respuesta era bastante escasa, alrededor del 15% hacia principios del año 2001.
Este análisis, bastante manual, lo repetimos de forma algo más automatizada, con motivo de nuestra participación en la Conferencia ISIC de 2008 celebrada en Vilnius y los resultados fueron más o menos similares, tal como podemos ver en el artículo que publicamos como resultado de la investigación en Information Research, la revista de Tom Wilson.
Analysis of the similarity of the responses of Web search engines to user queries: a user perspective” publicado en Information Research (vol. 13, nº 4, paper 382).
El artículo analiza la similitud de las respuestas proporcionadas por distintos motores de búsqueda ante consultas idénticas, desde una perspectiva centrada en el usuario. En un contexto caracterizado por el crecimiento exponencial de la información disponible en la Web y el uso masivo de motores de búsqueda como principal vía de acceso a contenidos digitales, los autores se plantean una cuestión clave: ¿ofrecen realmente los motores resultados similares cuando se formula la misma consulta?
El estudio parte de investigaciones previas que habían observado un bajo nivel de solapamiento entre los resultados de diferentes motores, sugiriendo que cada sistema devuelve conjuntos de documentos en gran medida distintos. Esta diversidad se atribuye a varios factores, entre ellos las diferencias en los índices utilizados (cada motor rastrea y almacena una porción distinta de la Web), los criterios de actualización de sus bases de datos y, sobre todo, los algoritmos de ranking que determinan el orden de aparición de los resultados.
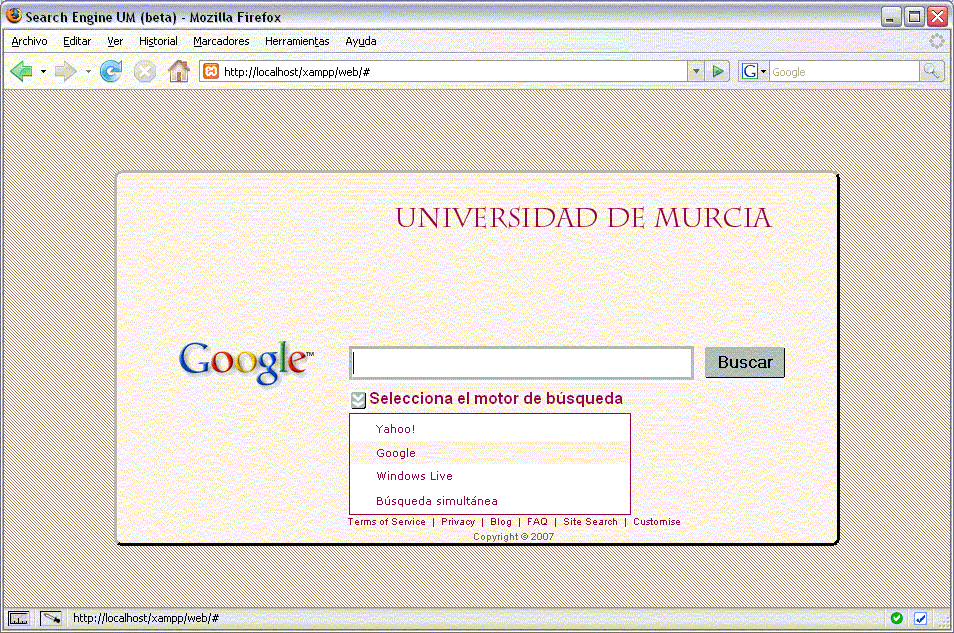
Para analizar empíricamente esta cuestión, los autores desarrollan un metabuscador experimental que permite enviar simultáneamente la misma consulta a varios motores de búsqueda y recopilar los resultados obtenidos. A partir de este sistema, se examinan dos dimensiones principales de similitud: (1) el grado de coincidencia en los documentos recuperados (es decir, si los mismos enlaces aparecen en diferentes motores), y (2) la similitud en la posición que ocupan esos documentos en las listas de resultados. Este segundo aspecto resulta especialmente relevante, dado que numerosos estudios sobre comportamiento de usuarios demuestran que la mayoría de las personas se limita a consultar los primeros resultados mostrados.
Los hallazgos confirman que el nivel de coincidencia entre motores es limitado. Incluso cuando se plantean consultas idénticas, los motores devuelven conjuntos de resultados considerablemente diferentes, tanto en términos de contenido como de ordenación. Esta falta de homogeneidad implica que la experiencia de búsqueda puede variar sustancialmente dependiendo del motor utilizado. Desde la perspectiva del usuario, esto significa que la elección del buscador no es neutral: puede influir en el tipo de información a la que se accede y en la visibilidad de determinadas fuentes.
El artículo también pone de relieve la complejidad del concepto de “cobertura” en la Web. Ningún motor indexa la totalidad de los contenidos disponibles, y las estrategias de rastreo y almacenamiento varían significativamente entre sistemas. Además, los algoritmos de ranking incorporan múltiples factores —como popularidad, enlaces entrantes, relevancia semántica u otros criterios propietarios— que introducen diferencias adicionales en la presentación de resultados. Así, la divergencia observada no es un error del sistema, sino una consecuencia estructural del funcionamiento de los motores de búsqueda.
Desde un punto de vista metodológico, el estudio contribuye a la evaluación comparativa de sistemas de recuperación de información en entornos web dinámicos. También subraya la necesidad de realizar análisis periódicos, ya que la Web y los motores evolucionan constantemente, lo que puede alterar los niveles de solapamiento y similitud con el tiempo.
En términos más amplios, el trabajo plantea implicaciones importantes para la alfabetización informacional y la comprensión crítica del entorno digital. Si diferentes motores ofrecen resultados distintos ante una misma consulta, los usuarios deberían ser conscientes de que la información accesible depende en parte de la herramienta utilizada. Esta constatación refuerza la idea de que los motores de búsqueda no son meros intermediarios neutrales, sino sistemas complejos que modelan el acceso al conocimiento.
En definitiva, el artículo demuestra que la diversidad entre motores de búsqueda es significativa y persistente, lo que invita a reflexionar sobre la naturaleza de la recuperación de información en la Web y sobre la importancia de adoptar una actitud crítica y comparativa en el uso de estas herramientas.