
El camino hacia la ciencia abierta amplía el foco de la comunicación científica hacia un nuevo paradigma: ya no se trata de publicar en abierto los artículos científicos para exponer y difundir los resultados de investigación, sino también de hacer públicos y accesibles los conjuntos de datos que sustentan la investigación. Estos conjuntos (o ‘datasets’ en la jerga) se han convertido en un elemento fundamental para mejorar la transparencia en la investigación (y la rendición de cuentas), facilitar la reproducibilidad y permitir la reutilización del conocimiento científico.

En nuestro contexto, el repositorio Zenodo desempeña un papel clave dentro de las infraestructuras de ciencia abierta. Desarrollado por el CERN (donde nació la web) y financiado por la Comisión Europea, permite depositar ‘datasets’, software, documentos y otros resultados de investigación, asignándoles un DOI que facilita su citación, preservación y difusión.
Hace un año (más o menos) analizamos en este blog la presencia de datasets generados por investigadores adscritos a las universidades públicas españolas en Zenodo (en las privadas se investiga menos). En ese estudio, con fecha de 31-12-2024, identificamos 6.944 contribuciones institucionales de conjuntos de datos y aportaba dos conclusiones principales: (1) el crecimiento progresivo del depósito de datos desde el año 2020 y (2) la existencia de grandes diferencias entre universidades en cuanto a su participación en este tipo de repositorios.
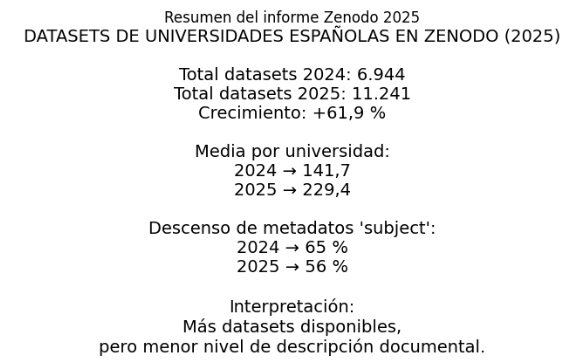
Hace pocos días, finalizamos un nuevo informe, actualizado hasta 31-12-2025, que confirma la aceleración de este depósito. En un año, el número total de conjuntos de datos de investigación asociados a investigadores de universidades públicas españolas ha pasado de 6.944 a 11.241 (62% de incremento). Esto refleja un cambio progresivo en las prácticas de investigación, impulsado tanto por políticas institucionales (ENCA) como por los requisitos de financiación y evaluación relacionados con la ciencia abierta. El hecho de que ANECA también los valore como mérito para sexenios y acreditación puede tener algo que ver, aunque quizá el efecto sea muy reciente.
Crece muy rápido el depósito de datos
La evolución anual muestra una tendencia claramente ascendente, especialmente a partir de 2020.
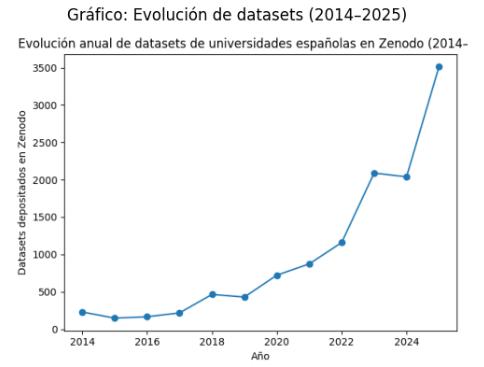
El pasado año 2025 destaca por el fuerte incremento de los conjuntos de datos de investigación depositados, que supera con mucho los valores registrados en años anteriores. Este crecimiento sólo es posible por la asunción por parte de los investigadores de la necesidad de considerar el depósito de los datos como parte natural del ciclo de investigación (además de la «obligación» que hay cuando recibimos financiación pública). El crecimiento no se concentra en unas pocas universidades, ha sido generalizado (incluso en aquellas que forman parte del «furgón de cola»). La media por universidad ha pasado de 141 a 229 conjuntos de datos, mientras que la mediana prácticamente se duplica. Esto significa que el depósito se extiende progresivamente por el conjunto del sistema universitario español.
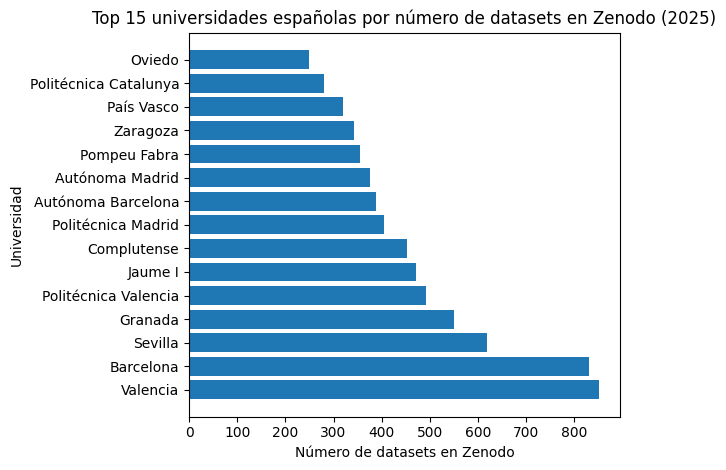
Se observa un aumento significativo del número de universidades de alta actividad. Si en 2024 solo dos superaban los 400 conjuntos de datos, en 2025 ya son siete, destacando especialmente Valencia, Barcelona, Sevilla, Granada y la Politécnica de Valencia. Esto apunta a la consolidación y aceptación de estrategias institucionales más activas en lo relacionado con la gestión de datos de investigación.
Más conjuntos de datos, pero menos descripción
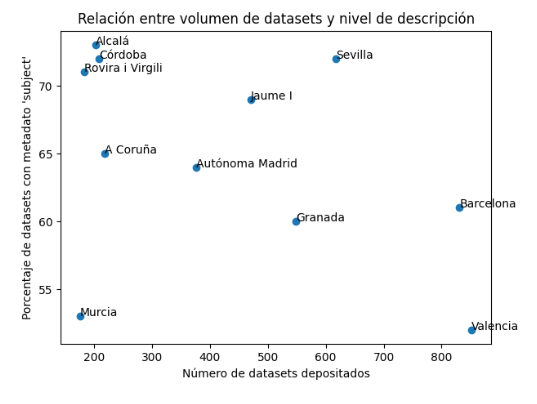
Los datos de este nuevo informe confirman una tendencia negativa: a medida que aumenta el volumen de conjuntos de datos depositados, la calidad de su descripción documental disminuye. Se ha utilizado como indicador la presencia del metadato ‘subject‘ en la descripción del conjunto de datos porque permite describir su contenido y facilita su posterior recuperación en el repositorio. En 2024, aproximadamente el 65 % incluían este tipo de metadatos, mientras que en 2025 la media desciende hasta un 56 %, quedando muy lejos en el tiempo aquellos años en los que este porcentaje alcanzaba el 75%. Esta tendencia a la baja sugiere que el crecimiento del volumen se produce más rápido que la adopción de buenas prácticas de documentación de los conjuntos de datos. Aunque cada vez se depositan más, no siempre se acompañan de una descripción suficiente que facilite su localización y reutilización.
Un indicador para analizar el equilibrio entre volumen y calidad
En el primero de los informes introdujimos un indicador sintético inspirado en la medida I₀ de Borko, originalmente diseñada para evaluar la eficacia de sistemas de recuperación de información, y que adaptamos a este contexto (lo denominamos igual un poco en «homenaje» a esta medida que utilizamos en nuestra tesis doctoral en una época muy, pero que muy lejana, el año 2002). Esta medida combina dos dimensiones: el volumen de conjuntos de datos depositados por cada universidad y el nivel de descripción documental de los mismos. Según este indicador, las que muestran un mejor equilibrio entre ambas dimensiones en 2025 son Sevilla, Jaume I, Barcelona, Autónoma de Madrid y Alcalá, que ocupan las primeras posiciones del ranking.
Conclusión
Los resultados muestran que el ecosistema de conjuntos de datos de investigación en el sistema universitario español crece con rapidez. Cada vez más investigadores efectúan el depósito en abierto en repositorios y varias universidades comienzan a consolidar estrategias institucionales para la gestión de datos. Sin embargo, el crecimiento cuantitativo debe ir acompañado de mejoras en la documentación y descripción de los conjuntos de datos. Si no se incorporan los metadatos adecuados, estos conjuntos de datos pueden ser técnicamente «abiertos», pero serán difíciles de encontrar, interpretar o reutilizar, para ello no hace falta el depósito.
El reto de los próximos años no será solo publicar más conjuntos de datos de investigación, sino también describirlos y publicarlos mejor.
Fuentes:
- Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2023). Implementación de los repositorios de datos de investigación en las universidades públicas españolas: estado de la cuestión. Scire: representación y organización del conocimiento, 29(2), 39-49. https://doi.org/10.54886/scire.v29i2.4914
- Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2023). (2025). #datasets de universidades españolas en Zenodo – 2024. Zenodo. https://doi.org/10.5281/zenodo.18085406
- Martínez Méndez, Francisco Javier: López Carreño, Rosana; Baptista, Ana Alice, Castelló Cogollos, Lourdes y Delgado Vázquez, Ángel M. (2026). #datasets de universidades españolas en Zenodo a 31-12-2025. Zenodo. https://doi.org/10.5281/zenodo.18903560
Nota técnica.
Cuando en un conjunto de datos de investigación aparecen investigadores de dos o más universidales, ese conjunto de datos se computa en cada institución. Por tanto, el número de conjuntos de datos total es algo inferior al que mostramos.

