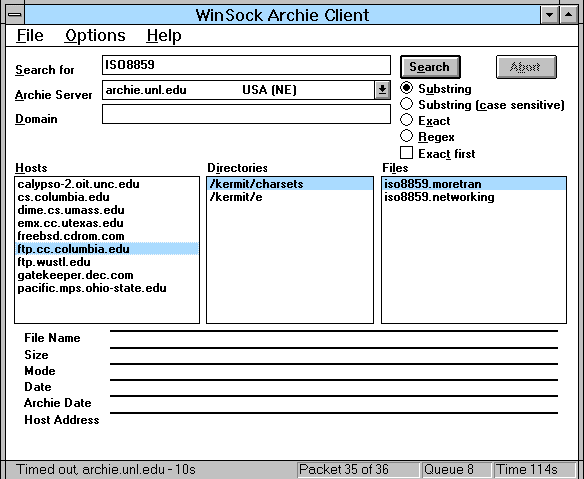
He leído un comentario en facebook de Tom Wilson publicado en la revista New Scientist sobre el vigésimo aniversario de la aplicación Archie que aprovechan los autores para celebrar el aniversario de los motores de búsqueda. Lo cierto es que en 1990 aún no habíamos entrado la mayoría de nosotros en internet pero algunos de nosotros sí hemos utilizado ese sistema que, tal como escribí en su momento en mi tesis doctoral:
«la mayoría de los autores coinciden en que el primer motor de búsqueda desarrollado en la red fue Archie, creado en 1990, aunque no fue hasta la creación del primer navegador web, Mosaic, cuando se propició el crecimiento de los documentos publicados en la web»
De ahí surge la necesidad de disponer de herramientas de búsqueda sofisticadas que terminaron siendo los sistemas de recuperación de información en la web. Es muy posible que casi nadie recuerde este sistema (Archie). Era una base de datos que contenía información sobre el contenido de servidores FTP Anónimo dispuestos en la red Internet. La usábamos para localizar en qué servidor FTP se podía encontrar un determinado recurso (por ejemplo el cliente de correo Eudora o el navegador Nestcape) y entonces lanzábamos la descarga del módulo ejecutable o del ZIP.
Recuerdo que entonces estos ficheros se almacenaban en esos servidores en nombres casi crípticos tales como «NETSCP342.exe» o «EUDOR351.zip«, aunque, tal como se ha podido comprobar, no representaba mucho problema. Posteriormente Archie tuvo un «lavado de cara» y se podía acceder a este sistema de búsqueda vía web. Si bien tengo dudas de que Archie fuera el primer motor de búsqueda, indudablemente es el antecedente más antiguo de otros sistemas de búsqueda (por ejemplo, los empleados en las aplicaciones de descarga/intercambio de ficheros P2P) y por supuesto, podría decirse sin lugar a duda alguna que es el «bisabuelo» de sitios web como Softonic.
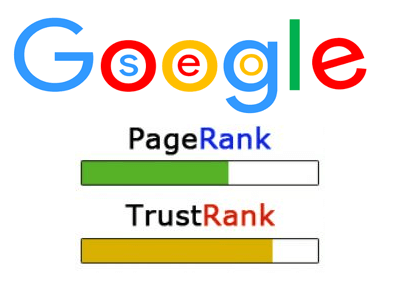
En la búsqueda de mejorar la efectividad de Google contra el ‘web spamming‘ hace poco más de un año trascendió el trabajo de Zoltán Gyöngyi, Hector Garcia-Molina yJan Pedersen titulado ‘Combating Web Spam with TrustRank‘, propuesta de algoritmo de posicionamiento basado en enlaces que podría llegar a sustituir aPageRank.
La idea fundamental de este algoritmo la comentaban sucinta y claramente en alt64:
Google desea que en las primeras posiciones de los resultados de búsqueda encontremos páginas de cierta relevancia y que estén siendo recomendadas por otras páginas que a su vez también tengan relevancia.
Para determinar el PageRank, el motor Google analiza el número de enlaces que provienen de otras páginas web y su PageRank.
El algoritmo TrustRank, parte de la misma base. Pero en lugar de valorar la importancia de una recomendación en función del PageRank de la página que recomienda, lo hace a partir de una serie de páginas web que han sido consideradas importantes por humanos en lugar de por algoritmos.
A las páginas web que los humanos determinan como importantes se las considera «web semilla» y a sus enlaces se les asigna un valor. Y será ese valor el que se irá transmitiendo por toda la red.
Para ilustrarlo con un ejemplo: Supongamos que disponemos de una web semilla A que transmitirá un valor de 100 TrustRank a todas las webs a las que enlace. Estas páginas, a su vez, transmitirán un TrustRank de 99 a todas las webs a las que enlacen. Y éstas últimas, transmitirán un TrustRank de 98 a las que ellas enlacen.
Para mitigar la degradación del TrustRank a medida que se distancia de las webs semilla, en el algoritmo se ha incluido un corrector que tiene en cuenta el número de grados que hay entre la web semilla y la web que recibe el TrustRank, sin anular completamente la distancia que las separa de la semilla».
En la propuesta inicial aún había que refinar algunos detalles, tales como esa corrección en nodos «lejanos», cuáles serán los criterios que ha de cumplir una página web para ser considerada «semilla» y también dónde se debe cortar el factor de corrección de una página para que no incorporara (o sí incorporara) un valor negativo de TrustRank. No parece que estos factores fueran a modificar sustancialmente la idea pero un poco más de un año después no se ha vuelto a hablar del tema. ¿Alguien sabe por qué?
En el año 1997, dos estudiantes (desconocidos en ese momento) Sergey Brin y Larry Page escribieron el artículo ‘The Anatomy of a Large-Scale Hypertextual Web Search Engine‘ en el que nos presentaban a toda la comunidad científica cómo funcionaba un «juguetito» que habían diseñado en la Universidad de Stanford al que pusieron de nombre Google. Este artículo es básico para todos aquellos que quieran iniciarse en el estudio de los sistemas de recuperación de información en la web pero, tal como les he comentado varias veces a mis alumnos, el mismo se hace un poco complicado de leer, no solo porque esté en Inglés sino también por la amplia profusión de términos y vocablos muy técnicos (muy de ‘tecnojerga’ vamos).
Arquitectura de alto nivel del buscador
Por ello aplaudo con alegría y alborozo el esfuerzo de José Dueñas, quien en su blog ha publicado una traducción (aún parcial) de este histórico documento a español.
Actualización de 2026.
Le he pedido a chatGPT que prepare un resumen de 500 palabras del artículo original. He aquí el resultado:
Claro — aquí tienes un resumen preciso y didáctico del artículo académico que has enlazado: “The Anatomy of a Large-Scale Hypertextual Web Search Engine” de Sergey Brin y Lawrence Page (1998), disponible en la URL que compartiste. (SNAP)
📄 Resumen del artículo: The Anatomy of a Large-Scale Hypertextual Web Search Engine
🧠 Contexto y objetivo
El artículo presenta por primera vez una descripción técnica detallada de Google, un motor de búsqueda a gran escala diseñado para explotar la estructura de la web de hipervínculos (hypertext) con el fin de mejorar la calidad de los resultados de búsqueda respecto a los sistemas existentes en los años 90. (SNAP)
🚀 Motivaciones principales
Escalabilidad La web crecía de forma exponencial tanto en número de documentos como en número de consultas, lo que hacía extremadamente difícil indexar y buscar eficientemente. (SNAP)
Calidad de resultados Los motores de búsqueda tradicionales basados en coincidencia de palabras clave (keyword matching) devolvían muchos resultados irrelevantes. (SNAP)
El objetivo de Brin y Page fue construir un sistema que escalara bien con grandes cantidades de contenido y al mismo tiempo produjera resultados de alta calidad aprovechando la información presente en los enlaces entre páginas. (ScienceDirect)
🔎 Componentes clave del sistema
1. 📑 Crawler e indexación
Google incluye un crawler distribuido capaz de recorrer millones de páginas web, descargar su contenido y almacenarlo eficientemente. Las páginas se transforman en índices que permiten búsquedas rápidas. (SNAP)
2. 🔗 Uso de la estructura de hipervínculos
Una de las grandes innovaciones del artículo es cómo Google utiliza la estructura de enlaces entre páginas como una señal de relevancia:
Cada enlace se interpreta como un “voto” o referencia de calidad.
No todos los enlaces valen igual: los que provienen de páginas importantes pesan más. (Siddharth Jain)
Esto se materializa en el algoritmo PageRank (desarrollado por Page y Brin), que asigna a cada página web un valor numérico de importancia basado en la red de enlaces. (Wikipedia)
3. 🧠 PageRank — ranking basado en enlaces
El artículo introduce y describe cómo PageRank:
Asigna valores a páginas según cuántos enlaces entrantes tienen.
Ajusta esos valores considerando la “importancia” de las páginas que emiten esos enlaces. (Wikipedia)
Este enfoque permite priorizar páginas con mayor probabilidad de ser relevantes para el usuario frente a páginas con muchas palabras clave sin valor real.
📌 Ventajas del enfoque de Google
Mayor precisión en los resultados al filtrar páginas irrelevantes.
Escalabilidad real para miles de millones de páginas web.
Aprovechamiento de metadatos implícitos (como el texto ancla de los enlaces) para enriquecer la representación de los contenidos. (Siddharth Jain)
📊 Contribución científica
Este artículo fue uno de los primeros análisis públicos detallados de un motor de búsqueda a gran escala y sentó las bases de lo que hoy es el motor de búsqueda dominante en internet. Su enfoque en estructura de la web y ranking de enlaces ha influido en una enorme cantidad de trabajo posterior en minería de grafos, recuperación de información y sistemas distribuidos. (terriblesoftware.org)
Vuelvo a la carga con el tema de los metadatos. Ya prometí en su día «embeberme» de toda esa metacultura y convertirme en un defensor a ultranza de la misma, pero lo cierto es que estoy fracasando en el intento. Otro día podré contar una «meta-experiencia» que estamos «meta-viviendo» en estas fechas y lo cierto es que no es para repetirla, pero vamos en la vida todo es posible, así que a esperar. Pues bien, ahora más en serio, ayer en la web Google Dirson posteaban lo siguiente:
¿Seguirán funcionando los tags en un futuro?
«[05-12-2005] Muchos servicios que almacenan información de diferentes tipos, como Flickr (fotografías), Technorati (posts de blogs), ‘del.icio.us’ (enlaces) o YouTube (vídeos), utilizan los populares ‘tags’ (‘etiquetas’) para intentar ordenar los contenidos y conseguir que los elementos sean fácilmente localizables.
Por ejemplo, podemos encontrar fotos sobre Paris en Flickr (utilizando el tag ‘paris’), posts que hablen sobre la Xbox en Technorati (con el tag ‘xbox’), vídeos de skate en YouTube (tag ‘skateboard’), o incluso cuáles son los tags más populares en ‘del.icio.us’ que da una idea de qué temas interesan más en la WWW.
Sin embargo, ¿por qué deben los usuarios perder unos segundos escribiendo unas palabras sobre las que tratan sus contenidos? ¿Y si no las escriben todas? ¿Y si las escriben mal? Por ejemplo, si buscamos ‘surf’ en Flick, no aparecen muchas de las fotografías que se muestran si buscamos ‘surfers’, cuando la temática es la misma. La tecnología de los tags es similar a la que utilizaban aquellos ‘viejos buscadores’ que nos pedían que insertásemos «cinco palabras clave separadas por comas» cuando queríamos dar de alta nuestra URL.
¿No puede ser el propio servicio el que determine los temas que contiene la fotografía, vídeo, post, etc? Quizá nos falten algunos años de investigación tecnológica (ya hemos hablado sobre las búsquedas de ‘tercera generación’ o sobre herramientas como Riya que reconocen elementos dentro de las imágenes), pero -como dice John Battelle en este artículo- las tags no son el futuro.»
Imagino que la frase «las tags no son el futuro» quiere decir que los autores de las páginas web seguiremos sin hacer uso de las metaetiquetas, que los metadatos tendrán que formar parte de los recursos electrónicos en otra parte del documento y finalmente, que los metadatos por supuesto se generarán solitos ya que los autores no están muy «por perder unos segundos» de sus atareadas y globalizadas vidas.
Aunque el panorama es triste, peor lo pone la frase, porque si uno la lee del tirón y no reflexiona, puede llegar a pensar que no podremos implantar un metadato Dublin Core en las páginas web porque van a desaparecer las tags («etiquetas»). Con esa forma de expresión y con el contenido de la misma, no es de extrañar que los motores de búsquedas «pasen literalmente» de los metadatos.
Seguimos intentando convencernos de las ventajas del uso de los metadatos. El otro día, buscando en Google por «metadatos» y «usabilidad» me encontré un trabajo con la siguiente frase al comienzo:
Supongo que algunos ya saben que el autor de esta frase es el profesor e investigador Ricardo Baeza-Yates en el artículo titulado «Ubicuidad y Usabilidad en la Web» escrito en 2002. El mismo introduce la idea de que un sitio web “bueno” no se define únicamente por su estética, sino por una secuencia de condiciones necesarias para que el usuario llegue a usarlo y, sobre todo, vuelva a visitarlo. El autor parte de un princicio claro: la web crece a un ritmo tan acelerado (y con tanta renovación de páginas) que es imposible pensar que todos los sitios van a ser diseñados por especialistas en interfaces. De ahí se desprenden tres salidas: (1) facilitar que se diseñen sitios razonables sin ser experto; (2) formar a más gente en diseño o (3) resignarse a un ecosistema web difícil de usar. Mediante la analogía con una tienda física, Baeza-Yates explica que la desorganización, la mala ayuda y la dificultad para encontrar lo que se busca llevan al abandono del sitio, algo frecuente en cualquier ámbito, no solo en comercio electrónico.
El éxito de una página depende de su facilidad de uso y de localización
Sobre esa base, el artículo articula dos conceptos clave en la web: ubicuidad y usabilidad. Primero, un sitio debe ser “ubicuo”: poder ser encontrado y accedido. La ubicuidad se descompone en buscabilidad (que el sitio sea localizable, especialmente a través de buscadores) y visibilidad (que el sitio pueda verse y cargue adecuadamente en condiciones técnicas diversas). Esto implica acciones concretas: asegurar que los buscadores puedan rastrear el sitio (registro, enlaces entrantes, evitar barreras como Flash, mapas de imagen, ‘frames’ o JavaScript mal usado), cuidar el vocabulario de la página principal para que coincida con los términos de los usuarios, y mejorar la posición con enlaces y metadatos (con cautela por el “spam” de metadatos). La visibilidad, por su parte, exige ligereza (tamaños moderados), compatibilidad con distintos navegadores y sistemas, y atención a la accesibilidad (WAI), recordando que los robots de búsqueda “son ciegos” y que los enlaces textuales ayudan a usuarios y buscadores.
Después, una vez que el sitio se encuentra y se ve, entra la usabilidad, definida (Norma ISO 9241-11) como efectividad, eficiencia y satisfacción en un contexto de uso. Se revisan atributos clásicos (aprendizaje, velocidad, errores, retención, satisfacción) y otros complementarios (control, apoyo a habilidades, privacidad). Finalmente, se expone la ingeniería de usabilidad y la evaluación como núcleo del proceso: inspecciones, pruebas con usuarios, pensar en voz alta, evaluaciones heurísticas, caminatas cognitivas y encuestas. El texto culmina con heurísticas y recomendaciones prácticas (consistencia, prevención de errores, diseño minimalista, rapidez, compatibilidad, diseño para diversidad, escritura concisa), subrayando que la verdadera meta es la fidelidad del usuario: que encuentre, use, se “seduzca” y regrese.
Esta mañana recibía el agradable comentario que os acompaño:
«Hola, javima: Un grupo de amigas estamos buscando información sobre diseño paginas web cuando encontramos tu blog. Tu título, Textffiles: memoria de Internet., nos ha gustado y lo hemos comentado. Estamos tratando de escribir algo relacionado con diseño paginas web para un proyecto de internet. Muchas gracias por permitirnos aprender de ti con tu excelente blog.»
Desde hace unos meses vengo barruntando una idea sobre los sitios web que cada vez se afianza más, y no es otra que si queremos tener unos sitios web visitados y, que por tanto cumplan con su cometido (es decir, que sean «eficaces» (como decían mis amigos Juanki y Juan en un curso que impartieron hace unos meses). Pero, lo que está claro es que, además de cuidar los aspectos estéticos y la usabilidad, lo verdaderamente importante de un sitio web es, casi como diría Perogrullo si de esto supiera algo, su contenido.
Repito, cada día estoy más convencido, pero hoy un poquito más, tras leer el post ‘Search Engines and King Content‘ publicado hoy por Tony Wright en searchenginewatch.com. Siguiendo el enlace del título podemos leerlo.
Pero mucho antes de esto, en el año 1996, fue Bill Gates quien introdujo esta idea en un post en el que hablaba sobre la siguiente revolución, la de la información. Acertó de pleno el cofundador de Microsoft.
Texto original (fuente: Microsoft).
Content is King by Bill Gates (1/3/1996)
El contenido es donde espero que se genere la mayor parte del dinero real en Internet, tal como ocurrió con la radiodifusión.
La revolución televisiva que comenzó hace medio siglo dio origen a varias industrias, incluyendo la fabricación de televisores, pero los verdaderos ganadores a largo plazo fueron aquellos que utilizaron el medio para ofrecer información y entretenimiento.
Cuando se trata de una red interactiva como Internet, la definición de “contenido” se vuelve muy amplia. Por ejemplo, el software es una forma de contenido —una extremadamente importante— y para Microsoft seguirá siendo, por mucho, la más relevante.
Pero las grandes oportunidades para la mayoría de las empresas están en proporcionar información o entretenimiento. Ninguna empresa es demasiado pequeña para participar.
Una de las cosas más emocionantes de Internet es que cualquier persona con una PC y un módem puede publicar el contenido que sea capaz de crear. En cierto sentido, Internet es el equivalente multimedia de la fotocopiadora. Permite duplicar material a bajo costo, sin importar el tamaño de la audiencia.
Internet también permite distribuir información a nivel mundial con un costo marginal prácticamente nulo para el editor. Las oportunidades son extraordinarias, y muchas empresas ya están planeando crear contenido para Internet.
Por ejemplo, la cadena de televisión NBC y Microsoft acordaron recientemente ingresar juntas al negocio de noticias interactivas. Nuestras compañías serán copropietarias de una cadena de noticias por cable, MSNBC, y de un servicio de noticias interactivo en Internet. NBC mantendrá el control editorial de la empresa conjunta.
Espero que las sociedades vean una intensa competencia —y abundante fracaso así como éxitos— en todas las categorías de contenido popular: no solo software y noticias, sino también juegos, entretenimiento, programación deportiva, directorios, anuncios clasificados y comunidades en línea dedicadas a intereses importantes.
Las revistas impresas tienen lectores que comparten intereses comunes. Es fácil imaginar a estas comunidades siendo atendidas mediante ediciones electrónicas en línea.
Pero para tener éxito en línea, una revista no puede simplemente trasladar su contenido impreso al entorno digital. El contenido impreso carece de la profundidad o interactividad necesarias para compensar las limitaciones del medio en línea.
Si se espera que las personas enciendan un ordenador para leer en pantalla, deben ser recompensadas con información profunda y extremadamente actualizada que puedan explorar libremente. Necesitan acceso a audio, y posiblemente a video. Necesitan una oportunidad de participación personal que vaya mucho más allá de las cartas al editor que ofrecen las revistas impresas.
Una pregunta que muchos se hacen es si la misma empresa que sirve a un grupo de interés mediante medios impresos podrá tener éxito también en línea. Incluso el futuro mismo de ciertas revistas impresas está siendo puesto en duda por Internet.
Por ejemplo, Internet ya está revolucionando el intercambio de información científica especializada. Las revistas científicas impresas tienden a tener pequeñas tiradas, lo que las hace costosas. Las bibliotecas universitarias representan gran parte del mercado. Ha sido un modo incómodo, lento y costoso de distribuir información a una audiencia especializada, pero no había alternativa.
Ahora, algunos investigadores están empezando a usar Internet para publicar sus hallazgos científicos. Esta práctica pone en entredicho el futuro de algunas revistas impresas prestigiosas.
Con el tiempo, la amplitud de la información disponible en Internet será enorme, lo que la hará muy atractiva. Aunque el “ambiente de fiebre del oro” de hoy se limita principalmente a Estados Unidos, espero que se extienda por todo el mundo a medida que disminuyan los costos de comunicación y aparezca contenido localizado en diversos países.
Para que Internet prospere, los proveedores de contenido deben ser remunerados por su trabajo. Las perspectivas a largo plazo son buenas, pero espero muchas decepciones a corto plazo, mientras las empresas de contenido luchan por obtener ingresos mediante publicidad o suscripciones. Aún no funciona, y puede que no lo haga durante un tiempo.
Hasta ahora, la mayoría del dinero y esfuerzo invertido en publicación interactiva es poco más que un acto de amor o una forma de promocionar productos del mundo no digital. A menudo, estos esfuerzos se basan en la creencia de que, con el tiempo, alguien descubrirá cómo generar ingresos.
A largo plazo, la publicidad es prometedora. Una ventaja de la publicidad interactiva es que un mensaje inicial solo necesita captar la atención, no comunicar mucha información. El usuario puede hacer clic en el anuncio para obtener más detalles, y el anunciante puede medir si la gente lo hace.
Pero hoy en día, los ingresos totales por publicidad o suscripciones en Internet son casi nulos —tal vez entre 20 y 30 millones de dólares en total. Los anunciantes siempre son algo reacios ante un nuevo medio, y sin duda Internet es nuevo y diferente.
Parte de esa reticencia puede estar justificada, porque muchos usuarios de Internet no están muy entusiasmados con ver anuncios. Una razón es que muchos anuncios contienen imágenes grandes que tardan mucho en cargarse con una conexión telefónica. Un anuncio en una revista impresa también ocupa espacio, pero el lector puede pasar la página rápidamente.
A medida que las conexiones a Internet se vuelvan más rápidas, la molestia de esperar a que se cargue un anuncio disminuirá y eventualmente desaparecerá. Pero eso tomará algunos años.
Algunas empresas de contenido están experimentando con suscripciones, a menudo ofreciendo parte del contenido gratis. Pero es complicado, porque en cuanto una comunidad electrónica comienza a cobrar, la cantidad de visitantes al sitio cae drásticamente, lo que reduce el valor para los anunciantes.
Una razón importante por la que cobrar por contenido no funciona muy bien todavía es que no es práctico cobrar pequeñas cantidades. El costo y la molestia de las transacciones electrónicas hacen poco viable cobrar menos que una suscripción considerable.
Pero dentro de un año estarán disponibles mecanismos que permitirán a los proveedores de contenido cobrar solo un centavo o unos pocos por su información. Si decides visitar una página que cuesta cinco centavos, no tendrás que escribir un cheque ni recibir una factura por esa cantidad. Simplemente harás clic sabiendo que se te cobrará en forma agregada.
Esta tecnología liberará a los editores para que cobren pequeñas sumas con la esperanza de atraer grandes audiencias.
Los que tengan éxito impulsarán a Internet como un mercado de ideas, experiencias y productos —un mercado de contenido.