Esta mañana ha venido a visitarme mi director de departamento a preguntarme si se explicaba algo sobre RAG en la asignatura Recuperación de Información de tercero del grado. Le he dicho que no pero que tenía previsto hacerlo a partir del próximo mes de septiembre. Como prueba de ello publico este vídeo que le pedí a Google LLM que creara a partir de una serie de fuentes de información que nos permiten saber cómo está cambiando el ecosistema de las búsquedas de información tras la irrupción de chatGPT et al. hace poco más de tres años.
RAG: la convergencia entre los motores de búsqueda tradicionales y los Modelos de Lenguaje Extensos (LLM).
RAG son las siglas en inglés de «Generación Aumentada por Recuperación», técnica empleada por las lA para mejorar la precisión de los LLM (modelos de lenguaje extensos) al conectarles fuentes de datos externas y actualizadas antes de generar una respuesta. Su uso reduce alucinaciones y proporciona información contextualizada, siendo ideal para datos privados o de empresa. Esta integración permite superar limitaciones históricas, como la información desactualizada o las respuestas inexactas, al fundamentar la IA en datos específicos y verificables.
LLM y motores de búsqueda
La relación entre los motores de búsqueda y los modelos de lenguaje extensos se define como simbiótica porque ambas tecnologías aprovechan las fortalezas de la otra para superar sus limitaciones individuales, creando sistemas de información más inteligentes y eficientes. Mientras que los motores de búsqueda ofrecen frescura y cobertura masiva de datos, los LLM aportan capacidades de comprensión del lenguaje natural y síntesis de información
LLM y recuperación de información: cambio de paradigma
Esta integración no es solo una mejora incremental, sino un cambio de paradigma hacia servicios de búsqueda centrados en el usuario . Sistemas como el nuevo Bing o Google AI Overviews son ejemplos de esta simbiosis en acción, donde el motor de búsqueda recupera la información más relevante y actual, y el LLM la procesa para ofrecer una interacción fluida y personalizada
La Editorial de la Universidad de Murcia (EDITUM) acaba de estrenar la serie de la Cátedra UNESCO en Gestión de la Información con la traducción del libro ‘Exploring Information Behavior‘ de Tom Wilson, obra de referencia en el campo del comportamiento informacional. Este texto analiza cómo las personas interactúan con la información en distintos contextos. Define la información como una señal modulada y recorre su evolución desde la tradición oral hasta la era digital. A través de diversos modelos teóricos, examina las etapas de búsqueda, los factores psicológicos y sociales implicados, así como las barreras de acceso. También incorpora la dimensión afectiva y fenómenos actuales como la desinformación. Finalmente, ofrece una guía metodológica para investigar cómo se descubre, procesa y utiliza la información en la vida cotidiana.
¿Qué es el comportamiento informacional?
El comportamiento informacional puede entenderse como la interacción humana con las fuentes, canales y contextos de información. Incluye la búsqueda activa, el descubrimiento incidental, el uso, la comunicación, el intercambio y también la evitación de información.
Esta definición es amplia a propósito. No se limita al uso de bibliotecas, bases de datos o buscadores académicos, incorpora también acciones cotidianas como preguntar a otra persona, consultar una web, leer un mensaje, recibir una recomendación algorítmica o decidir no acceder a determinada información.
Idea clave: la información no solo se busca; también se encuentra, se interpreta, se comparte y, en ocasiones, se evita.
La información como señal: una definición operativa
Uno de los planteamientos más interesantes de Wilson es su definición funcional de información como una «señal modulada que puede ser interpretada por un receptor«. Esta idea permite entender la información más allá del documento escrito o del recurso digital.
Desde una señal biomédica en un monitor hospitalario hasta la luz de una estrella analizada por un astrónomo, pasando por el lenguaje oral, el texto impreso o una imagen digital, la información depende de la existencia de un receptor capaz de interpretarla.
Implicación principal: el comportamiento informacional comienza antes de la búsqueda consciente, porque las personas reciben, procesan e interpretan señales constantemente.
El ser humano como animal informacional
Wilson plantea una idea especialmente potente: todas las sociedades humanas han sido siempre sociedades de la información. La llamada sociedad de la información no representa, por tanto, una ruptura absoluta, sino una intensificación tecnológica de una característica estructural de la vida humana.
Desde la tradición oral hasta la escritura, desde la imprenta hasta la web, las sociedades han dependido de la producción, transmisión y conservación de información para sobrevivir, organizarse, aprender y tomar decisiones.
Esta perspectiva permite conectar el comportamiento informacional con procesos antropológicos, sociales, educativos y tecnológicos. La información no es solo un recurso documental: es una condición de la acción humana.
Tipos de comportamiento informacional
El comportamiento informacional adopta formas muy diversas. Puede manifestarse como búsqueda activa, cuando una persona consulta una fuente para resolver una necesidad concreta; como descubrimiento pasivo, cuando recibe información sin haberla solicitado explícitamente; o como interacción social, cuando obtiene o comparte información mediante conversaciones, redes personales o trabajo colaborativo.
En el entorno digital actual, estas formas se mezclan continuamente. Una persona puede iniciar una búsqueda en Google, encontrar información recomendada por una red social, contrastarla con otra persona y terminar utilizando una herramienta de inteligencia artificial para sintetizarla.
Esta complejidad confirma una de las tesis centrales del libro: el comportamiento informacional no es lineal, sino situado, iterativo y dependiente del contexto.
Factores que condicionan el comportamiento informacional
El comportamiento informacional no es uniforme. Está condicionado por factores personales, contextuales y emocionales. Entre los factores personales se encuentran el nivel educativo, la experiencia previa, las competencias informacionales o la percepción de autoeficacia. Entre los factores contextuales destacan el acceso a recursos, el entorno social, la cultura organizativa o las condiciones materiales de búsqueda.
La dimensión emocional también desempeña un papel decisivo. La ansiedad, el miedo, la incertidumbre o la confianza pueden activar, bloquear o modificar la búsqueda de información. Por ejemplo, una persona que recibe un diagnóstico médico puede buscar información de forma intensiva, apoyarse en grupos de ayuda o, por el contrario, evitar información por miedo a lo que pueda descubrir.
Conclusión clave: el comportamiento informacional es situacional, dinámico y profundamente humano.
Modelos de comportamiento informacional
Uno de los aspectos más sólidos de Explorando el comportamiento informacional es que Thomas D. Wilson no construye su propuesta en aislamiento, sino que la inserta dentro de una tradición teórica amplia y acumulativa. Esto permite entender el comportamiento informacional no como un fenómeno único y cerrado, sino como un campo interpretativo en el que convergen distintos modelos, cada uno enfocado en dimensiones específicas del proceso.
El propio modelo de Wilson actúa como marco integrador. En él, la necesidad de información no aparece como un punto de partida abstracto, sino como una consecuencia directa del contexto vital de la persona. Las necesidades informativas emergen de situaciones concretas: trabajo, enfermedad, aprendizaje, toma de decisiones o participación social. A partir de ahí, el modelo incorpora factores intervinientes, como la disponibilidad de recursos, las barreras cognitivas y sociales, la motivación o la autoeficacia, que pueden facilitar o bloquear la búsqueda.
Este enfoque permite entender por qué, ante una misma necesidad, distintas personas adoptan comportamientos completamente diferentes. Una persona puede buscar información en una base de datos especializada, otra puede consultar a un experto y otra puede no buscar nada porque carece de recursos, competencias o confianza suficiente.
Wilson complementa su planteamiento con otros modelos ampliamente consolidados en la literatura. Uno de los más influyentes es el modelo del proceso de búsqueda de información de Carol Kuhlthau, que introduce una dimensión especialmente relevante: la afectiva. Frente a visiones puramente racionales, Kuhlthau muestra que la búsqueda de información está atravesada por emociones cambiantes, desde la incertidumbre inicial hasta la confianza final. Esta incorporación de lo emocional resulta clave para comprender comportamientos reales en contextos de alta implicación personal.
En una línea complementaria, el modelo de Gary Marchionini aporta una visión dinámica del proceso. La búsqueda no se concibe como una secuencia lineal de pasos, sino como una actividad iterativa en la que el usuario reformula continuamente sus estrategias a medida que interactúa con los sistemas de información. Esta idea resulta especialmente actual en entornos digitales, donde explorar, probar, comparar y ajustar la consulta forman parte de la experiencia cotidiana.
Para estructurar conceptualmente estas acciones, Wilson recurre también a la teoría de la actividad desarrollada por Yrjö Engeström. Este enfoque permite descomponer el comportamiento en niveles —actividad, acciones y operaciones— y situarlo dentro de un contexto social determinado. Gracias a esta perspectiva, se evita una simplificación excesiva del comportamiento informacional y se reconoce su carácter situado y contextual.
En el origen mismo del proceso informativo, el modelo de necesidades de información de Robert S. Taylor resulta especialmente esclarecedor. Taylor plantea que la necesidad de información no surge siempre de forma completamente definida, sino que evoluciona desde estados difusos o viscerales hasta formulaciones explícitas. Esta evolución explica por qué muchas búsquedas comienzan con términos vagos o imprecisos y se refinan progresivamente.
Finalmente, Wilson incorpora principios generales como el principio del mínimo esfuerzo formulado por George Zipf. Este principio sostiene que las personas tienden a minimizar el esfuerzo en sus actividades informativas, lo que se traduce en la preferencia por fuentes accesibles o familiares, incluso cuando no son necesariamente las más rigurosas. En el contexto actual, esta idea ayuda a explicar el predominio de ciertos canales digitales frente a fuentes más especializadas.
En conjunto, lo que emerge de esta integración no es un modelo único y cerrado, sino una arquitectura conceptual compleja en la que se combinan dimensiones cognitivas, emocionales, sociales y contextuales. Esta es una de las principales aportaciones de Wilson: mostrar que el comportamiento informacional solo puede comprenderse plenamente cuando se analiza como un proceso multidimensional, dinámico y condicionado por el entorno en el que se produce.
La dimensión afectiva del comportamiento informacional
El libro concede una importancia especial a la dimensión afectiva. Buscar información no es una operación neutra ni exclusivamente racional. Las emociones forman parte del proceso desde el inicio: la incertidumbre puede activar la búsqueda, la confusión puede dificultarla y el alivio puede aparecer cuando la información encontrada permite comprender mejor una situación.
Esto es especialmente visible en contextos sensibles, como la salud, el trabajo social, la educación o la toma de decisiones personales. La información no solo sirve para resolver problemas prácticos, sino también para reducir ansiedad, confirmar decisiones o proporcionar seguridad.
Por esta razón, cualquier análisis del comportamiento informacional que ignore los factores emocionales resulta incompleto.
Implicaciones en la era de la inteligencia artificial
Las ideas de Wilson resultan especialmente relevantes en el contexto actual de inteligencia artificial, buscadores generativos y modelos de lenguaje. Los sistemas digitales no eliminan el comportamiento informacional humano; lo reorganizan mediante nuevos intermediarios tecnológicos.
Los buscadores, las plataformas sociales, los sistemas de recomendación y los modelos generativos actúan como mediadores entre las personas y el universo de la información disponible. La persona ya no interactúa únicamente con documentos o expertos, sino también con algoritmos que filtran, jerarquizan, resumen y recombinan contenidos.
Desde esta perspectiva, el comportamiento informacional ayuda a comprender cómo las personas formulan preguntas, cómo evalúan respuestas, cómo confían o desconfían de las fuentes y cómo utilizan la información generada por sistemas de inteligencia artificial.
Claves para GEO: Generative Engine Optimization
El marco de Wilson también ofrece principios útiles para la optimización de contenidos en entornos de inteligencia artificial generativa. La Generative Engine Optimization, o GEO, no consiste solo en posicionar páginas en buscadores tradicionales, sino en facilitar que los contenidos sean comprendidos, seleccionados, sintetizados y citados por modelos de lenguaje.
Desde esta perspectiva, un contenido optimizado para GEO debe ofrecer definiciones claras, estructura semántica, contexto explícito, ejemplos interpretables y referencias conceptuales reconocibles. También debe evitar ambigüedades innecesarias y presentar la información en unidades reutilizables.
El comportamiento informacional es, por tanto, un campo especialmente útil para el diseño de contenidos orientados a LLM, porque permite comprender cómo las personas formulan necesidades de información y cómo los sistemas pueden responder a ellas de forma más precisa.
Resumen en vídeo
Le he pedido a Google LLM que elabore un breve resumen en vídeo con el contenido esencial de lo que el autor considera que es el comportamiento informacional, el cómo se desarrollan las «fuerzas ocultas» que desencadenan nuestro modo de buscar información.
Conclusión
Explorando el comportamiento informacional ofrece un marco imprescindible para comprender cómo interactuamos con la información en la actualidad. Su principal aportación consiste en mostrar que buscar información no es una acción aislada, sino un proceso complejo, contextual, emocional y profundamente humano.
Comprender este proceso es esencial para diseñar mejores sistemas de información, mejorar la alfabetización informacional, crear contenidos más claros y optimizar la visibilidad en entornos dominados por buscadores, algoritmos y modelos de inteligencia artificial.
Hace unos días escuché a unas de las personas que se presenta a las elecciones al rectorado de la Universidad de Murcia comentar en una entrevista en un podcast que quizá estábamos escribiendo páginas web bajo el paradigma equivocado porque son muchos los usuarios que emplean las gramáticas generativas IA tipo chatGPT, Gemini, Claude, Perplexity, etc. para recuperar información en lugar de los motores de búsqueda tradicionales y podemos preparar nuestras entradas de forma optimizada para esta nueva tecnología, avanzando desde el SEO hasta el GEO (siglas de ‘Generative Engine Optimization‘).
Desde entonces vengo preguntándome sobre esta cuestión y voy a decicar algunas entradas (redactadas en el formato «tradicional» de este blog, pero intentando tomar nota de algunas de las recomendaciones que he encontrado al respecto) a esta cuestión.
Claves del cambio de paradigma
Sabemos que los buscadores tradicional devuelven listas de enlaces a partir de palabras clave y la correspondencia entre esas palabras y el contenido de las páginas web. Una gramática generativa LLM devuelve respuestas construidas a partir de fragmentos de información. Esta diferencia es substancial y deja claro que estamos comparando tecnologías diferentes. Ahora, sin dejar de conferir importancia a la entrada en sí misma como unidad, para las gramáticas generativas resulta más trascendente que el contenido pueda ser reutilizado como una unidad de conocimiento.
1. Credibilidad: si no es verificable, no sirve.
Los modelos generativos priorizan contenidos en los que se puede “confiar”, prefieren textos con fuentes identificables, contenidos con datos concretos y de autoría clara, como se comprueba en esta búsqueda en el modo IA de Google:
Ejemplo de búsqueda en el «modo IA» de Google.
Además de elaborar un resumen para responder a la cuestión, muestra en la parte derecha de la pantalla las fuentes de información que le sirven de soporte. Entre los criterios que necesitamos los autores para ganarnos esa «confianza» destacan:
citar informes, artículos o datasets
incluir cifras, porcentajes o resultados medibles
indicar quién escribe y cuándo
Está claro que cuanto más verificable sea nuestro contenido, más probable es que sea reutilizado. Esto es algo habitual en el mundo científico al escribir un artículo, el mismo debe apoyarse en fuentes de autoridad contrastada que terminan confiriéndole a nuestro trabajo la calidad suficiente para ganar calidad en el seno de la comunidad científica. Esto no es frecuente en la web actual. Por cierto, he usado viñetas en lugar de escribir en un párrafo los criterios «de confianza» para las gramáticas LLM, lo he hecho porque esa forma de exponer el contenido también les parece interesante.
2. Estructura: escribir pensando en fragmentos, no en páginas.
Las gramáticas generativas no “leen artículos”, trabajan con fragmentos (‘chunks‘). Los autores podemos, fácilmente, ayudar a ello usando los encabezados (H1, H2, H3, …) de una forma clara y consistente (de hecho, cualquiera que siga este blog verá que hay más encabezados que de costumbre, antes no hacía tanto uso de ellos). Dividir el contenido en bloques pequeños y evitar referirnos a esos bloques (párrafos) con expresiones ambiguas del estilo de “esto último permite” o “lo anterior indica” servirá para aumentar el interés de esas gramáticas hacia nuestra entrada web, esto no contradice para nada lo que hemos venido haciendo hasta ahora. La novedad fundamental reside en estructurar en formato pregunta–respuesta estos fragmentos de información, por ejemplo:
Formato de redacción «pregunta-respuesta» en una entrada web.
Este tipo de bloques de contenido encaja perfectamente con cómo funcionan los sistemas RAG (Retrieval-Augmented Generation), técnica que mejora la precisión de los modelos LLM en la consulta de fuentes de datos externos.
3. Claridad: menos retórica, más información.
Para un lector humano, cierto grado de estilo es positivo, aunque siempre se ha comentado que la web no es el lugar para perífrasis y circunloquios. Para una gramática generativa LLM lo importante es encontrar contenidos con:
frases claras
conceptos explícitos
poca ambigüedad
Asím funciona mejor la frase «Un eclipse solar ocurre cuando la Luna bloquea la luz del Sol desde la Tierra” que el texto «Este fenómeno sucede cuando se alinean ciertos cuerpos celestes”. Redactar sencillo genera contenido de fácil comprensión y mayor reutilización. La clave es la densidad informativa (cuánta información útil y concreta hay en una frase o texto en relación con su longitud).
4. Metadatos para ayudar a las máquinas a entender el contenido.
Si bien no es obligatorio, añadir metadatos estructurados, lo cierto es que ayuda bastante. Aquí entramos en el territorio de Schema.org y de los datos estructurados que sirven para indicar (entre otras cosas):
tipo de contenido (artículo, dataset, etc.)
autor
fecha
tema
Este enriquecimiento de los sitios web con microdatos reduce la ambigüedad del texto y mejora la interoperabilidad con sistemas externos. En este caso, esto es positivo tanto para las gramáticas generativas como para la recuperación de información tradicional.
5. Pensar en RAG: cómo “leen” realmente estos sistemas.
Muchos sistemas actuales combinan modelos de lenguaje con recuperación de información RAG. Esto implica:
el contenido se fragmenta
el contenido se convierte en vectores (‘embeddings‘)
del contenido se van a recuperar los fragmentos más relevantes
el modelo genera la respuesta
Lo cierto es que los autores no podemos controlar este proceso, pero sí facilitarlo por medio de:
bloques de contenido de tamaño medio (ni demasiado largos ni demasiado cortos)
repetir ligeramente conceptos clave (sin forzar)
responder preguntas que el usuario realmente haría
Lo cierto es que las dos primeras recomendaciones también son válidas para la recuperación de información tradicional, es la tercera (que ya hemos adelantado) la que representa una novedad: escribir pensando en preguntas concretas.
6. Qué ya no funciona (o funciona peor)
Algunas prácticas del SEO clásico pierden sentido aquí:
keyword stuffing (uso excesivo de palabras clave) → irrelevante o incluso perjudicial
textos largos sin estructura → difíciles de reutilizar
contenido genérico sin datos → baja probabilidad de uso
Tanto el exceso de palabras clave como la desestructuración de los textos sabemos desde hace tiempo que estaba penalizado en la recuperación de información clásica. En el contexto GEO podemos considerar su abolición como una premisa. En GEO, más no es mejor: mejor es mejor.
Resumiendo …
Todo esto se puede resumir así en una frase corta: «No escribas páginas. Diseña unidades de conocimiento«. Para ello, debemos seguir, como mínimo, esta serie de pasos:
Hacer el contenido verificable (fuentes, datos, autoría).Q
Estructurar el texto en bloques claros (mejor si son preguntas y respuestas).
Escribir de forma explícita y sin ambigüedades.
Facilitar la fragmentación del contenido (‘chunking’).
La optimización del contenido para las gramáticas generativas no sustituye completamente al SEO, lo que hace es añadir una nueva capa.
Para finalizar, le he pedido a Google Notebook LLM que prepare un pequeño vídeo para mostrar la transición del SEo al nuevo paradigma GEO a `partir de algunas de las fuentes que hemos empleado para preparar esta entrada. Creo que ha quedado interesante.
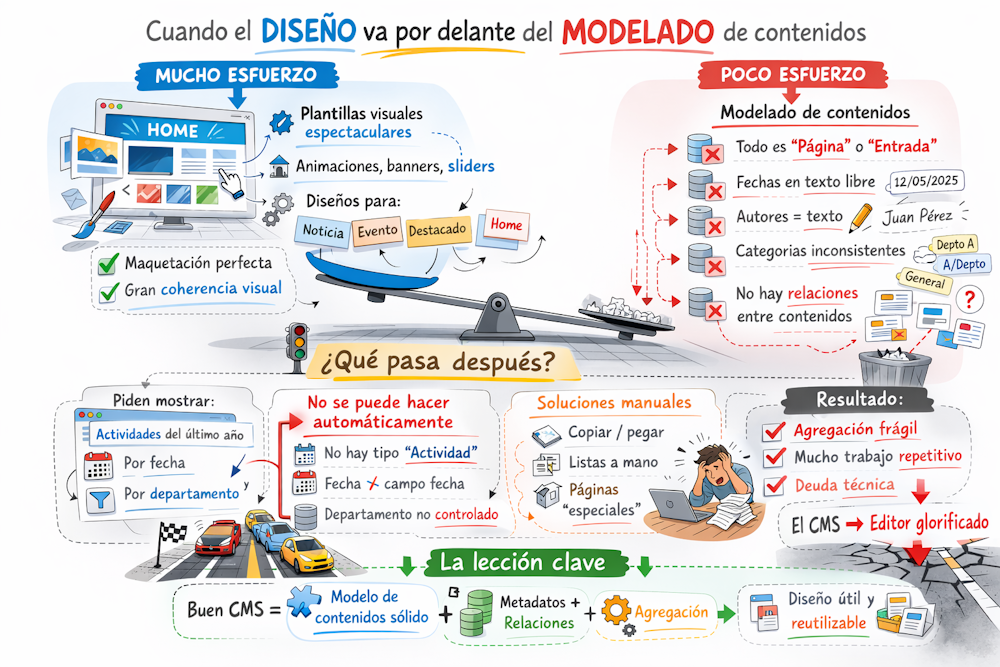
Aprovecho que estoy preparando las clases de esta semana en la asignatura «Sistemas de Gestión de Contenidos» del 2º curso del grado en Gestión de Información y Contenidos Digitales para reflexionar brevemente sobre una cuestión: ¿qué pasa cuando se dedica muchas horas a un diseño «muy visual» del sitio web con nuestro CMS y «pasamos» un poco (o un bastante) del modelado del contenido?.
No es raro encontrarnos sitios web donde se ha puesto todo el interés en un diseño visual muy atractivo que atrae, sin duda alguna, a nuevos usuarios pero que, a nivel de modelado de contenidos, presenta graves problemas. Cuando el diseño va por delante, nos centramos en el desarrollo de unas plantillas visuales espectaculares, animaciones, banners y carruseles de diapositivas de gran calidad visual, maquetación de la interfaz web atractiva, todo ello dentro de una gran coherencia visual (el «tema» del CMS).
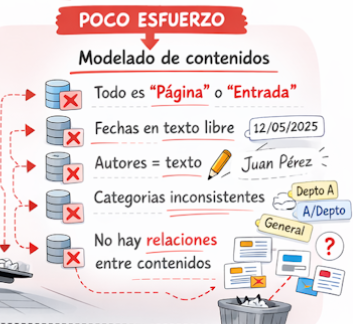
Si el sitio web no va más allá de un blog, un pequeño catálogo de productos o una pequeña web institucional, no se plantearían muchos problemas. En estos casos, puede resultar suficiente con los tipos de contenido base «página» y «entrada» (‘post’), con introducir las fechas en formato de texto libre («12/06/2025» o «12-jun-26», a elección del usuario incluso), no tener normalización alguna de cómo introducir el nombre de un autor de un libro («Juan Antonio Pérez López» o «Juan A. Pérez López» o «Pérez López, Juan Antonio»), que la taxonomía del sitio web no esté muy trabajada (o sin trabajar directamente, dejando a los usuarios construirla sin consistencia alguna) y, finalmente, no existe relación entre tipos de contenido específicos (básicamente por su escasez o ausencia). En definitiva, mucho diseño y poca gestión de información, algo parecido a lo que le está ocurriendo ahora al equipo Aston Martin de F1, que ha contratado un «mago» del diseño como Adrian Newey y unos motores Honda que no son capaces de llevar a cabo quince vueltas seguidas a un circuito.
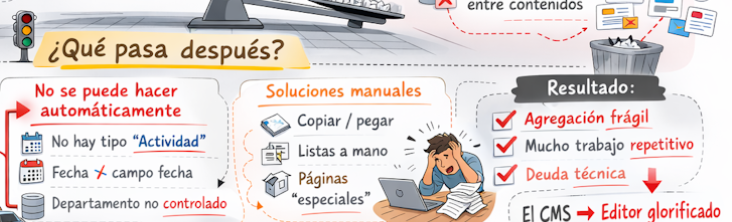
En estos sitios web, poco más se puede hacer que navegar por las distintas secciones, usar el buscador o esperar que la nube de etiquetas esté construida con algún criterio. Si quisiéramos consultar un histórico de «actividades culturales»desarrolladas en el último año, tendríamos el problema de que no existe ese tipo de contenido específico y que, además, la búsqueda por fechas puede resultar complicada al no esta normalizado el formato de entrada.
La solución suele terminar siendo manual, se copia contenido de entradas que recuperamos (manualmente casi siempre) de la web para pegarlo en listas elaboradas a mano (como si trabajáramos con el editor de texto normal, de ahí el apelativo de «glorificado» de la imagen). El resultado final es escasa y frágil agregación de contenidos (poco se puede extraer por medio de consultas automáticas), mucho trabajo repetitivo, algo que debería obviar el uso de un CMS, produciéndose una situación de «deuda técnica», algo parecida a la que Honda tiene ahora con la escudería Aston Martin y con todos los aficiones a la Fórmula 1 que ven que Fernando Alonso difícilmente podrá aspirar a un podio en esta su última temporada (o no) en los circuitos.
Siguiendo con esta metáfora, hay que intentar que el diseño del CMS no nos obligue con un coche normal en las carreras. Para ello hace falta modelado de contenido adeucado, metadatos bien definidos, relaciones entre tipos de contenidos, vistas del contenido a partir de agregación, todo ello en un marco de diseño web útil y reutilizable.
Actualizo una entrada antigua de este blog que escribí en el año 2006 sobre la cierta confusión existente sobre si, en una búsqueda, recuperamos información o datos. Vamos a ver cómo queda.
En el campo de la recuperación de información (‘information retrieval‘), casi al principio de la disciplina, era normal encontrar autores que empleaban la expresión «recuperación de datos» cuando en realidad de lo que estaban hablando era de recuperar información. Teniendo en cuenta las fechas de lasque hablamos (años 80, cuando el tecnopop), Esto se debía, fundamentalmente, a una clara influencia de la terminología informática, disciplina cuya rapidísima evolución llevó a muchos autores a cometer el error de considerar sinónimos ambos conceptos, llegándose a olvidar, como afirmaba Brookes, que se puede recuperar información sin emplear procedimientos informáticos (hecho indiscutible aunque no sea lo más común hoy en día, evidentemente).
El frecuente y necesario empleo de una tecnología no sustituye la obligatoriedad de utilizar adecuadamente los conceptos terminológicos. Un ejemplo de este desacierto lo hallamos en el Glosario ALA que define “information retrieval” como “recuperación de la información» en su primera acepción y como “recuperación de datos” en una segunda, considerando sinónimos ambos términos en lengua inglesa. De parecida opinión es el Diccionario Mac Millan de Tecnología de la Información, que considera la recuperación de información como el conjunto de “técnicas empleadas para almacenar y buscar grandes cantidades de datos y ponerlos a disposición de los usuarios”.
Afortunadamente, es mayor el grupo de autores que establecen diferencias entre ambos conceptos. Entre ellos destaca Meadow, para quien la recuperación de la información es “una disciplina que involucra la localización de una determinada información dentro de un almacén de información o base de datos”. Este autor establece de forma implícita una ligazón entre recuperación de información y el concepto de «selectividad» a la hora de presentar esa información al usuario siguiendo algún tipo de criterio discriminatorio (selectivo por tanto) entre una gran colección de documentos. Meadow marca un poco más estas diferencias, al afirmar que no es lo mismo la recuperación de información entendida como traducción del término inglés information recovery que cuando se traduce el término information retrieval, porque “en el primer caso no es necesario proceso de selección alguno”. Pérez-Carballoy Strzalkowski refuerzan esta idea afirmando que “una típica tarea de la recuperación de información es traer documentos relevantes desde una gran archivo en respuesta a una pregunta formulada por un usuario y ordenar estos documentos de acuerdo con su relevancia”.
Grossman y Frieder indican que la recuperación de información es “hallar documentos relevantes, no encontrar simples correspondencias a unos patrones de bits”. De similar criterio es el W3Cque define recuperar información como “dado un conjunto de documentos y una pregunta, encontrar el conjunto de documentos más relevantes con la pregunta”.
En clase, explico a mis estudiantes que, en la recuperacíón de datos, las preguntas son altamente formalizadas y la respuesta es directamente toda la información deseada. Así, “recuperar los títulos de los libros escritos por Jorge Luis Borges en la década de los 50” sería la ecuación “SELECT titulo WHERE autor=’Jorge Luis Borges’ AND fecha>1949 AND fecha<1960”. Otra pregunta fácil es saber cuántos ciudadanos de Murcia tienen alguna multa de tráfico sin abonar al Ayuntamiento de la ciudad y cuánto totaliza esa deuda para las arcas municipales. Nos movemos en un paradigma determinista, el territorio del modelo relacional de bases de datos. También les explico que en la recuperación de información, las preguntas son más difíciles de trasladar a un lenguaje formal y la respuesta es un conjunto de documentos que probablemente contendrá la información deseada, siempre con un factor de cierta indeterminación. En este modelo, el territorio de los SRI, La consulta sería, por ejemplo, «Obras Borges década 50”.
El gran profesor ‘Keith’ Rijsbergen establece en la siguiente tabla las diferencias entre recuperar datos e información:
Finalizo siempre esta cuestión presentando la siguiente cita de Ricardo Baeza-Yates:
“dada una necesidad de información (consulta + perfil del usuario + … ) y un conjunto de documentos, ordenar los documentos de más a menos relevantes para esa necesidad y presentar un subconjunto de aquellos de mayor relevancia”
¿Sigue este tema vigente?
Creo que esta distinción conceptual sigue siendo especialmente pertinente hoy en día. Si se observa la evolución reciente de los sistemas de búsqueda y acceso a la información. Las tecnologías actuales —como la búsqueda semántica, el uso de representaciones vectoriales (embeddings) o los modelos de lenguaje de gran tamaño (LLMs)— no han eliminado el problema clásico de la recuperación de información, sino que han añadido nuevas capas de complejidad. Estos sistemas ya no se limitan a la coincidencia literal entre términos (‘matching‘), sino que operan sobre representaciones semánticas del contenido, aproximándose con mayor eficacia a la noción de relevancia, aunque sin resolverla plenamente.
Datos, información y recuperación en sistemas de búsqueda actuales. Imagen elaborada por chatGPT.
Muchos de los SRI contemporáneos combinan, de forma híbrida, procedimientos propios de la recuperación de datos y de la recuperación de información. La indexación estructurada, las búsquedas exactas o las consultas sobre bases de datos conviven con mecanismos de ranking, inferencia semántica y estimación de relevancia. Esta convergencia tecnológica no invalida la distinción conceptual entre ambos enfoques; al contrario, la hace más necesaria, ya que permite comprender mejor los límites, fortalezas y riesgos interpretativos de cada tipo de sistema. En este contexto, los sistemas basados en modelos de lenguaje de gran tamaño y arquitecturas de retrieval-augmented generation (RAG) reintroducen, bajo nuevas formas, el debate clásico entre datos e información. Aunque estos modelos pueden generar respuestas coherentes y contextualmente plausibles, su funcionamiento depende en gran medida de procesos previos de recuperación y selección de documentos relevantes. La calidad informativa del resultado no reside únicamente en la capacidad generativa del modelo, sino en la adecuación del proceso de recuperación que lo alimenta, confirmando la vigencia de los principios fundamentales de la recuperación de información.
Fuentes bibliográficas.
[1] Brookes afirma esto en la presentación del primer capítulo de la obra Information Retrieval Research titulado ‘Information Technology and Information Science’, donde recuerda que el problema de la recuperación de información no ha de aplicarse sólo a lo automático, sino también a lo manual. (Oddy et al, 1981). Salton también lo recalca al comentar que no siempre se recupera información textual (Salton & McGill, 1983).
Durante la década de los años 80, además del tecno-pop, va cogiendo fuerza la idea de que el hipertexto puede ser la mejor solución para la gestión de la información porque la tecnología ya comenzaba a ofrecer soluciones para ello y porque cada vez se veía más claro que las bases de datos relacionales no se ajustaban bien del todo a las exigencias de unos sistemas de información cada vez más grandes y más multimedia. En aquella época es cuando surgen los primerossistemas de hipertexto de uso más o menos corriente:
IBM BookMaster (1980s). Herramienta de autoría de documentos con capacidades de hipertexto y estructuración. Estaba concebida para crear manuales técnicos y documentación corporativa pero que introdujo ideas que posteriormente aparecieron en otras herramientas de hipertexto.
Guide (1982). Sistema desarrollado por Peter J. Brown en la Universidad de Kent y comercializado por Owl International, fue pionero en la navegación hipertextual estructurada. Se usaba para crear documentos extensos y complejos, como manuales técnicos y enciclopedias, en los que los usuarios exploraban la información por medio de enlaces integrados en el texto. Recuerdo de este sistema (llegué a usarlo a principio de los años 90) que introdujo el concepto de «expansión y contracción» del texto, en el que las secciones vinculadas se desplegaban o contraían dentro del mismo documento, ofreciendo una experiencia fluida sin necesidad de cambiar de pantalla (algo que no hace la web). Esta característica era especialmente útil para gestionar grandes cantidades de información de manera organizada y estos enlaces de expansión eran tremendamente útiles y sólo los vemos ahora en las barras de menús.
NoteCards (1984). Creado en el mítico Xerox PARC, fue otro sistema pionero que permitía gestionar ideas interconectadas con informaciones mediante «notas» que podían representar texto, imágenes o gráficos y estaban organizadas en «tarjetas» vinculadas por enlaces. Estaba programado en LISP (uno de los lenguajes de programación más emblemáticos en el campo de la IA creado por John McCarthy, uno de los padres de estas «inteligencias») y permitía a los autores usar comandos de este lenguaje para personalizar o crear tipos de nodos completamente nuevos (recuerda en algo las IA de gramática generativa, ¿verdad?).
HyperCard (1987). Fue la aplicación más conocida aunque solo funcionaba en los ordenadores Macintosh. Desarrollado por Bill Atkinson para Apple era una aplicación que combinaba características de bases de datos, programación y diseño multimedia. Así, permitía crear «pilas» de tarjetas interconectadas. En estas tarjetas podía haber texto, imágenes y botones interactivos que conducían a otras tarjetas, creando así una experiencia de navegación hipertextual. Si bien no pudimos usarlo en nuestra entonces pequeña escuela universitaria (no había presupuesto para adquirir un ordenador de la empresa de la «manzanita»), sí tuve ocasión de leer un manual del sistema. El mismo destacaba enormemente por su facilidad de uso y, además, incluía el lenguaje de programación HyperTalk que permitía a usuarios sin experiencia técnica crear aplicaciones personalizadas. Esta flexibilidad lo convirtió en una herramienta popular para la enseñanza, el desarrollo de juegos y la creación de aplicaciones interactivas. Influyó en el diseño de interfaces gráficas y en la concepción de la web al popularizar los enlaces que conectan diferentes piezas de información.
La disponibilidad de una tecnología capaz de gestionar la información de forma gráfica y, especialmente, que propiciase una lectura de forma no estrictamente secuencial, «cierra el ciclo» y termina «conectando» en el tiempo de Vannevar Bush y Ted H. Nelson con Tim Berners-Lee, joven (entonces) investigador británico que trabajaba en el CERN a principios de los 90 y quien asistía incrédulo a principios de esta década a la paradoja de comprobar día a día cómo en este laboratorio (un lugar donde todos los días se llevan a cabo pequeños milagros”, escucha el imaginario historiador Robert Langdon de boca de un también imaginario director del CERN en la novela “Ángeles y demonios” de Dan Brown), perdía información o tenía problemas para localizar proyectos desarrollados por científicos de muy alto nivel tras costosísimas horas de trabajo.
A Berners-Lee le desesperaba que esa “maravillosa organización” adoleciera de este problema, especialmente cuando en ella trabajaban miles de personas de alta cualificación intelectual, muy creativas la mayoría. Si bien estaban organizados en una estructura jerárquica, esto no limitaba la manera en la que se comunicaba y compartía información, equipo y software en todos los grupos. En realidad, más que de una jerarquía, la estructura de trabajo real del CERN era una red conectada que, además, aumentaba su tamaño con el paso del tiempo.
En este entorno, una persona que se incorporase a este laboratorio, como mucho recibía alguna pista sobre quiénes serían contactos útiles para recabar información verbal de lo disponible acerca de su proyecto y poco más: el resto consistía en un proceso de autoaprendizaje. Por entonces, no se tomaba esto como un problema porque las investigaciones del CERN alcanzaban un éxito notable (y alcanzan hoy en día), a pesar de los malentendidos ocasionales y de la duplicación de esfuerzos en la transmisión interna del conocimiento, sin olvidar las pérdidas de información (los detalles técnicos de proyectos anteriores a veces se perdían para siempre o sólo se recuperaban tras llevar a cabo una investigación típica de detective en una emergencia). El problema se agrandaba por la alta rotación de este personal investigador (muchos investigadores solo llegan a dos años de estancias en este centro).
También detectó otro problema que había pasado desapercibido: el modo de registrar la documentación de un proyecto. Si un experimento analizaba un fenómeno estático y particular, toda la información se podía registrar en un libro para posteriores consultas, pero esto no era lo frecuente. Cuando había que introducir un cambio en un proyecto que afectaba a una pequeña parte de la organización (cambiar una parte del experimento o comprar un nuevo detector de señales), el investigador debía averiguar qué otras partes de la organización y otros proyectos se iban a ver afectados. Con el tipo de libro de registro utilizado era prácticamente imposible de mantener actualizado y no ofrecía respuestas a cuestiones
Con el paso del tiempo esto se hubiera hecho insostenible. Era un problema a resolver en ese momento que no podía ser visto como un hecho aislado. La supervivencia de una organización de investigación está íntegramente ligada a su capacidad de mejorar su gestión de información. Para hacerla posible, el método de almacenamiento no debería imponer restricciones a la información. Una «red» de notas con enlaces (referencias) entre los documentos era una solución mucho más útil que un sistema jerárquico fijo (tipo carpetas de un administrador de ficheros).
Para describir un sistema complejo, muchas personas recurren a diagramas con círculos y flechas, esto permite describir relaciones entre los objetos de una manera que las tablas o directorios no pueden. Si llamamos a los círculos “nodos” y “enlaces” a las flechas e imaginamos cada nodo como una pequeña nota o pieza de información (da igual que sea un artículo, un resumen o una foto), se puede construir un sistema vinculado de información entre personas y piezas informativas en constante evolución. Así, la información de un proyecto no residirá sólo en una carpeta de documentos que difícilmente un nuevo investigador iba a reutilizar, ahora formaría parte de la red informativa organizacional en la que se establecerían vínculos entre otras personas y departamentos, garantizando la supervivencia de la información. Esta propuesta de sistema de almacenamiento iba va a conseguir implantar, al fin, la idea del hipertexto como sistema de gestión de información.
Lo verdaderamente curioso, algo que poca gente conoce, es que cuando Berners-Lee presentó su memorándun ‘Information Management: a proposal‘, su jefe de equipo le dio permiso para hacerlo «cuando no tuviera algo más importante que hacer«.
Contenido de calidad para Google es el que cumple con los principios de utilidad, relevancia y confiabilidad, mientras se optimiza para las necesidades de los usuarios. Este concepto ha evolucionado con el tiempo e incluye ahora una atención especial al alineamiento con los principios E-E-A-T.
(a) Los principios E-E-A-T: Experiencia, Conocimientos, Autoridad y Confiabilidad
Experiencia (‘experience’): es bueno que el creador del contenido posea experiencia práctica y directa en el tema tratado. Esto incluye anécdotas, casos de uso y resultados obtenidos de primera mano, relevantes sobre todo en industrias como portales de viajes o productos especializados.
Conocimientos(‘expertise’): relacionado con el anterior principio, es conveniente que el contenido sea escrito por alguien con un conocimiento técnico o especializado en el tema (en medicina un médico o un investigador biosanitario, en derecho un magistrado o un fiscal, etc.). También se puede traducir como «pericia».
Autoridad (‘authoritativeness’): principio vinculado con la reputación del creador y de la fuente. Incluye menciones por otros expertos y enlaces entrantes de sitios confiables. Google valora el contenido que sea verdadera referencia dentro de un sector. Google evalúa la autoridad analizando factores como la calidad de las fuentes que enlazan al contenido y las menciones del autor o sitio web en medios confiables. Un sitio web o creador de contenido que es considerado la fuente definitiva en un tema tiene una autoridad muy alta.
Confiabilidad (‘trustworthiness’): principio relacionado con la precisión y seguridad del contenido. Aquello sitios web con errores, datos imprecisos o que no usen el protocolo seguro https, afectan negativamente a la percepción del contenido. La confianza se evalúa con base en la precisión, honestidad, seguridad y fiabilidad del contenido del sitio web en general. Factores como la transparencia en la información de contacto, la explicación de políticas claras, la seguridad del sitio web y la concreción y precisión en la información proporcionada (‘clickbaits‘ fuera por favor), contribuyen a la confiabilidad.
Factores y Criterios de Evaluación del Contenido de Calidad
En la siguiente tabla recogemos los factores clave que Google considera para valorar la calidad del contenido de un sitio web en la primera columna. En la segunda presentamos el enfoque distintivo del análisis de cada autor como factor particular o estrategia central resaltada como clave para mejorar la calidad del contenido.
Autor
Principales Factores de Calidad
Enfoque Distintivo
Iqra Jamal
Narrativa atractiva, datos originales y actualización constante.
Uso de ‘storytelling‘ para conectar emocionalmente con el usuario.
Search Engine Journal
Intención de búsqueda, estructura organizada y contenido optimizado técnicamente.
Adaptación a diferentes etapas del viaje del usuario.
Slickplan
Uso de multimedia, organización lógica y profundización temática.
Diseño visual como una herramienta de engagement clave.
Stellar Content
E-E-A-T, claridad de lenguaje y relevancia cultural.
Localización cultural del contenido para mayor resonancia.
ContentGo
Autoridad, confiabilidad y optimización semántica.
Enfoque en el uso de datos verificados por expertos reconocidos.
La web Backlinko dedica una página informativa sobre los factores de alineamiento de Google ofreciendo una guía exhaustiva de más de 200 elementos que influyen en el algoritmo. Su propósito es «educar» a las personas que administran sitios web y a profesionales del SEO sobre cómo mejorar la posición de sus páginas en los resultados de búsqueda. En este análisis dividen los factores en categorías clave, como la calidad del contenido, ‘backlinks‘ y la experiencia del usuario (UX) y aspectos técnicos tales como la velocidad de carga y la optimización para el escosistema móvil. También se analizan señales de comportamiento del usuario y actualizaciones constantes del algoritmo.
El ranking de Google dibunado por Delle – 3
En la siguiente tabla recogemos una síntesis de los once (como si fuera una alineación de un equipo de fútbol) factores que más se destacan en este artículo.
Factor
Descripción
Ejemplo
Calidad del Contenido
Google prioriza contenido de alta calidad, informativo y relevante.
Un artículo detallado y bien investigado sobre un tema específico que responde completamente a las preguntas de los usuarios.
‘Backlinks‘ (enlaces entrantes)
Los enlaces de otros sitios web actúan como votos de confianza. Cuantos más enlaces de entrada de alta calidad tenga tu sitio, mejor se posicionará.
Un sitio web que recibe enlaces de universidades y sitios de noticias reconocidos.
SEO Técnico
Aspectos técnicos del sitio web, como la velocidad de carga, la compatibilidad con dispositivos móviles y la capacidad de rastreo.
Un sitio web optimizado para cargar rápidamente en dispositivos móviles y que utiliza un archivo robots.txt adecuado para permitir el rastreo de los motores de búsqueda.
Optimización de palabras clave
Uso de palabras clave relevantes en el contenido del sitio web para ayudar a los motores de búsqueda a entender de qué trata el sitio.
Un blog de recetas que utiliza palabras clave como “recetas saludables” y “comida vegana” en sus artículos.
Experiencia del usuario (UX)
Medida de lo fácil y agradable que es para los usuarios utilizar el sitio web. Google prefiere sitios que proporcionan una buena experiencia de usuario.
Un sitio web con una navegación intuitiva, tiempos de carga rápidos y diseño responsive.
Marcado de esquema (Schema Markup)
Datos estructurados que se pueden añadir al sitio web para ayudar a los motores de búsqueda a entender mejor el contenido.
Un sitio de comercio electrónico que utiliza marcado de esquema para mostrar reseñas de productos y precios directamente en los resultados de búsqueda.
Señales sociales
Interacciones sociales como “me gusta”, “compartir” y otros. Aunque no son un factor directo, pueden influir en la visibilidad del contenido.
Un artículo que recibe muchas comparticiones en redes sociales como Facebook y Twitter.
Señales de marca
La percepción general de la marca en línea. Google favorece marcas bien conocidas y respetadas.
Un sitio web de una marca reconocida que recibe menciones en medios de comunicación y tiene una fuerte presencia en redes sociales.
Edad del dominio
Los dominios más antiguos pueden tener una ligera ventaja, ya que se consideran más confiables.
Un sitio web que ha estado activo durante más de 10 años y ha mantenido un historial constante de contenido de calidad.
Velocidad de carga del sitio
La rapidez con la que se carga un sitio web es un factor importante, especialmente en dispositivos móviles.
Un sitio web que utiliza técnicas de optimización como la compresión de imágenes y el almacenamiento en caché para mejorar los tiempos de carga.
Intención de búsqueda
La capacidad del contenido para satisfacer la intención del usuario en el momento de la búsqueda.
Un artículo que proporciona una guía completa y detallada sobre “cómo plantar un jardín de hierbas” cuando los usuarios buscan información sobre jardinería.
RTabla resumen de los 11 factores más importantes en el ranking de Google. Fuente: Backlinko
Como pasa con las selecciones de fútbol donde cualquier aficionado o aficionada tiene su propio «once«, si buscamos en otras páginas web es más que seguro que algunas de estas características no sean consideradas por sus autores e incluyan otras que hemos dejado fuera. Es ley de vida.
Evan Bailyn, CEO de la empresa de SEO ‘First Page Sage‘, escribió en diciembre de 2021 un artículo en Linkedln una nota informatica titulada ‘The 2022 Google Algorithm Ranking Factors‘ donde presentaba los factores ordenados a partir de su «peso» en la fórmula final del algoritmo de ranking, que podemos visualizar en el siguiente diagrama circular.
Como se observa, un 26% de la fórmula final se debe al contenido de calidad (de alto nivel se menciona), un 17% se le asigna a las metaetiquetas del título de la página, los enlaces de entrada (‘backlinks‘) tienen un peso del 15% (con Pagerank era el factor clave, desde 2018 ha descencido mucho en importancia). También tiene importancia la presencia de esa página entre lo que se considera «nichos de expertos» (13%) y la involucración de los usuarios (fidelidad) que alcanza el 11%. Entre estos cinco factores suman un poco más del 75% del peso de la fóruma final según Evan Bailyn. Aquí va la tabla completa.
¿Qué es «contenido de calidad» para Google?
Son varios aspectos a considerar:
Se trata de contenido original, único y valioso. Google da preferencia al contenido nuevo y único. Es conveniente crear entradas que respondan a las preguntas de sus lectores, que aporten valor y que sean originales. Como regla general, Google premia el contenido de liderazgo intelectual producido al menos dos veces por semana. Si tu contenido es similar al de otras páginas web, causará un impacto negativo en tu SEO. Para empezar, el motor podría no indexar y clasificar la página y ralentizará la tasa de rastreo de su sitio web (la web se hará “obsoleta”). Por lo tanto, cuando creemos contenido, ha de ser diferente y mejor que el de otros sitios web clasificados para el término de búsqueda. Ya lo avisaba Bill Gates en 1996 en su frase «Content is king» (que viene a ser I Ley Universal de la Gestión de Contenidos en la Web para mis alumnos).
Hay que mantener el contenidofresco y actualizado. Si las publicaciones se actualizan y se añade habitualmente información nueva, se envía una señal positiva al motor de búsqueda. La frescura del contenido juega un papel importante si en nuestras entradas se tratan noticias o tendencias. En estos casos, Google prefiere las páginas que proporcionan la información más reciente. Por ejemplo, si escribimos sobre la crisis sanitaria mundial, nuestro contenido debe contener noticias e investigaciones recientes. Una forma sencilla de encontrar la información más reciente para mantener tu contenido fresco es utilizar Google Trends.
La longitud del contenido es otro factor clave. Una de las preguntas recurrentes en SEO ha sido siempre si la extensión del contenido forma parte de los factores de clasificación de Google. La respuesta es “SÍ”. Según diferentes estudios, los posts con 1.890 palabras de media se sitúan en la primera página de resultados. Dicho esto, no hay una regla rígida por la que debamos ceñirnos a un límite de palabras. Lo mejor es crear contenido con profundidad y que cubra un tema con gran detalle. Google prefiere las páginas que responden completamente a la pregunta del usuario y proporcionan soluciones detalladas.
Relación entre la longitud de una entrada web y la posición en la respuesta de Google.
La estructura del contenido y su organización también influye en la valoración de su calidad. Las entradas deben estar bien organizadas y estructuradas. Esto facilita a los visitantes la lectura y la búsqueda de soluciones a sus problemas. Para mejorar la estructura y la organización de estos artículos, se pueden utilizar distintos niveles de encabezado (H2, H3, H4, etc.) para agrupar el contenido. Mantener debidamente actualizado el fichero sitemap.xml ayuda también. También podemos utilizar etiquetas HTML para viñetas y listas numéricas para organizar aún más el contenido. Esto es beneficioso ya que Google recoge estas listas y las muestra como fragmentos destacados para diferentes palabras clave.
Uno de los libros fundamentales sobre recuperación de información es la obra ‘Language and representation in information retrieval’ de D.C. Blair de 1990. Y una de sus principales aportaciones es, sin duda alguna, el llegar a establecer una clara diferenciación entre el término ‘data retrieval’ y el término ‘information retrieval’, utilizando como criterios distintivos:
En recuperación de datos se usan preguntas altamente formalizadas, cuya respuesta es directamente la información deseada. En cambio, en recuperación de información las preguntas resultan difíciles de trasladar a un lenguaje normalizado (aunque existen lenguajes para ello son de naturaleza mucho menos formal que los empleados en los sistemas relacionales) y la respuesta es un conjunto de documentos que pueden contener, sólo probablemente, lo deseado, con un evidente factor de indeterminación.
De lo anterior y según la relación entre el requerimiento al sistema y la satisfacción de usuario, la recuperación de datos es determinista y la recuperación de información es posibilista, por causa del nivel de incertidumbre presente en la respuesta.
En cuanto al éxito de la búsqueda, en recuperación de datos el criterio a emplear es la exactitud de lo encontrado, mientras que en recuperación de información, el criterio de valor es el grado en el que la respuesta obtenida satisface las necesidades de información del usuario, es decir, su percepción personal de utilidad, más conocido como la relevancia de la respuesta..
Diferencias entre búsquedas de datos y de información. Imagen elaborada con chatGPT.
Jesús Tramullas destaca un aspecto de las reflexiones de Blair, “la importancia, en ocasiones ignorada, que tiene el factor de predicción por parte del usuario, ya que éste debe intuir, en numerosas ocasiones, los términos que han sido utilizados para representar el contenido de los documentos, independientemente de la presencia de mecanismos de control terminológico. Este criterio de predicción es otro de los elementos que desempeñan un papel fundamental en el complejo proceso de la recuperación de información” y que no se presenta en el campo de la recuperación de datos.
Sin duda alguna, el honor de haber propuesto el primer método de evaluación de los sistemas de recuperación de información en la web le corresponde a Heiting Chu y Marilyn Rosenthal, quienes en el año 1996 (prácticamente en el inicio del desarrollo de los buscadores web) publicaron el trabajo ‘Search Engines for the World Wide Web: A Comparative Study and Evaluation Methodology‘ con motivo de la conferencia ASIS’96.
Se compararon tres sistemas de búsqueda (AltaVista, Excite y Lycos), midiendo sus capacidades de búsqueda (por ejemplo, lógica booleana, truncamiento, búsqueda por campos, búsqueda de palabras y de frases) y de su rendimiento en la recuperación de información (es decir, precisión y tiempo de respuesta), utilizando consultas de ejemplo extraídas de preguntas reales de referencia.
La exhaustividad (recall), el otro criterio clásico de evaluación en recuperación de información, se omite deliberadamente en este estudio, ya que resulta imposible suponer cuántos ítems relevantes existen para una consulta determinada dentro del enorme y cambiante sistema de la web. Ya adelantaba este estudio pionero la poca utilidad de calcular esta ratio en este contexto (nadie aspira a consultar la mayor parte de la respuesta, con la primera y/o segunda página de resultados va a ser suficiente).
Los autores del estudio constataron que AltaVista superaba a Excite y Lycos tanto en las funcionalidades de búsqueda como en el rendimiento de recuperación, aunque Lycos presentaba la mayor cobertura de recursos web entre los tres motores de búsqueda analizados.
Como resultado de esta investigación, se propuso además una metodología para evaluar otros motores de búsqueda web no incluidos en el presente estudio.