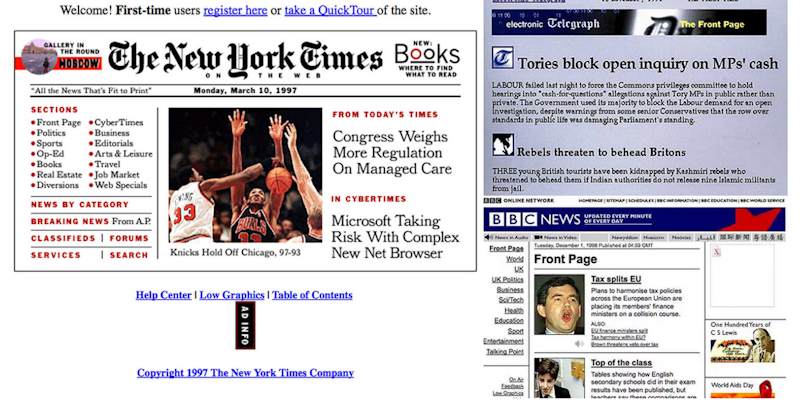
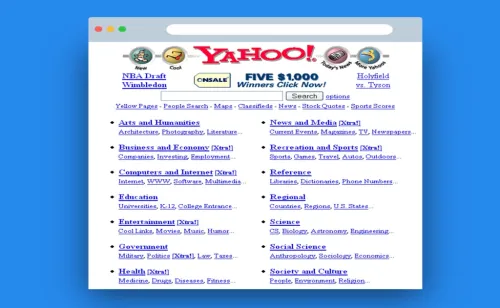
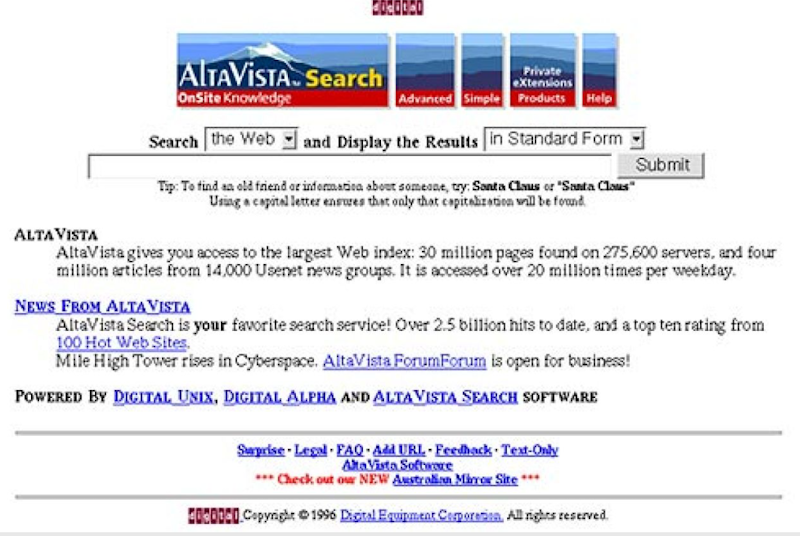
En otra entrada comentamos que la expansión de la web a principios de los años 90 pronto desbordó el entorno académico, hábitat natural de internet, y comenzó a expandirse por otros ámbitos: administraciones, empresas, medios de comunicación y particulares (algo más adelante con los blogs), publicándose páginas y sitios web por su cuenta.
En estos primigenios sitios de la «Web 1.0” era frecuente incluir una página con enlaces a otras páginas que parecían interesantes y podían permitir ampliar información a los lectores, a modo de «misceláneas«. Se puede que esto era replicar, en cierto modo, el muy tradicional servicio de referencia que desde tiempos inmemoriales llevan a cabo las personas que trabajan en las bibliotecas. Esto constituyó el germen para el desarrollo de los primeros sistemas de recuperación de información (SRI) en la web: los índices o directorios, sistemas de los cuales Yahoo!fue durante un tiempo el mejor ejemplo.
Estos SRI, como muchos recordamos todavía, son un producto documental considerado una fuente de información de carácter secundario porque dirige a la fuente original, justo lo que hacían y actualmente hacen estos sistemas de recuperación. Una actividad de gestión de información vuelve a confluir con la tecnología de la web. Se llevaba a cabo un seguimiento generalista y se registraban apenas unas pocas páginas de cada sitio web, a diferencia de los motores de búsqueda cuyo propósito es indexar la totalidad de un sitio web (o intentarlo al menos).
Con el paso del tiempo, el vertiginoso crecimiento de la web hizo imposible el rastreo manual de los nuevos sitios que iban surgiendo ni la actualización del contenido ya rastreado. El día que Yahoo! se convirtió en motor de búsqueda tras comprar Altavista, comenzó el final definitivo de estos sistemas.
En noviembre de 2014 estuve de visita en la Universidade Estadual Paulista «Julio de Mesquita Filho», más concretamente en el Campus de Marilia. El motivo de la misma fue participar en el Programa de Posgrado de Ciencias de la Información, impartiendo una conferencia el segundo día de mi estancia y un seminario sobre recuperación de datos y recuperación de información al final de la misma. Antes de proseguir quiero agradecer a los compañeros y estudiantes brasileños sus muchas atenciones hacia mi persona, son unos grandes anfitriones y mejores personas.
Faculdade de Filosofia e Ciências – Universidade Estadual Paulista «Júlio de Mesquita Filho» – Câmpus de Marília (UNESP).
Fragmento de la portada de la propuesta de Tim Berners Lee sobre la WWW
He revisado algunos errores en la redacción original del texto de la conferencia y la he publicado en el respositorio Digitum de nuestra universidad. Espero que guste, hice un amplio recopilatorio de hitos y conceptos alrededor de la gestión y de la recuperación de información.
Dedicamos una entrada al enriquecimiento de los sitios web con microdatos y, si bien pienso que creo quedó bastante completa, también es verdad que quedó algo teórica de más. Vamos a intentar mostrar algunas aplicaciones prácticas. Lo primero que vamos a hacer es recordar qué es un ‘Rich Snippet‘.
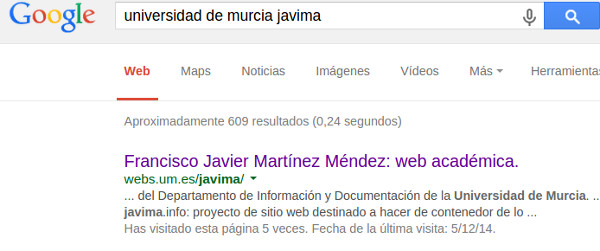
En la jerga de la web un ‘snippet‘ es el pequeño resumen informativo que aparece en un motor de búsqueda cuando se localiza una página web. Cuando «delegamos» en el motor la tarea de elaborar ese resumen de forma automática suele incluir las primeras palabras que encuentra en la página y lo cierto es que no suelen quedar muy bien, que digamos, Por ello, existe la posibilidad de personalizar de alguna manera esa presentación informativa aportando nosotros los datos, es decir, aportando microdatos.
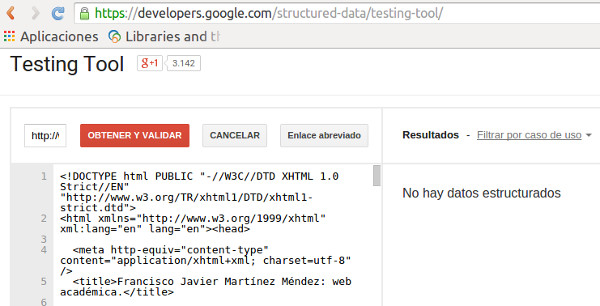
En estos resultados observamos que Google ha elegido algunas palabras de la presentación de esta página como las más representativas para diseñar el ‘snippet’. Esto se debe a que no ha encontrado texto enriquecido que el administrador de la misma haya querido destacar de alguna manera para que aparezca resaltado en la presentación de la misma por parte del motor de búsqueda. De hecho, si usamos la herramienta ‘Testing Tool’ de Google para verificar la presencia de microdatos, éste sería el resultado:
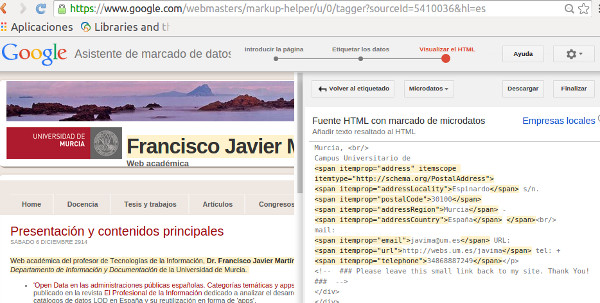
Continuando con la tecnología que ofrece Google para trabajar con datos estructurados, encontramos un asistente para introducir este tipo de código en las páginas. Una vez hemos accedido a esta página nos encontramos con un pequeño inconveniente, el asistente solicita la URL (o el fragmento de texto) a enriquecer y el tipo de página web que queremos enriquecer (si se trata de una página de negocio local, de serie de televisión, de películas o de eventos, entre otras limitadas opciones que ofrece la iniciativa schema.org). Podemos entonces hacer dos cosas, incluir nosotros los microdatos directamente como hicimos en el post anterior (algo lento y farragoso), o bien intentar adaptarnos a lo más parecido de la «oferta» que disponemos. En nuestro caso vamos a optar por lo segundo y elegimos «Negocio local».
Aparecen dos subventanas, una es la página a enriquecer con microdatos, la otra es el asistente con los elementos de descripción previsto para «Empresa o Negocio local». De lo que se trata ahora es de ir marcando textos o imágenes en la subventana de la izquierda e ir asignándole elementos (marcas) en la subventana de la derecha, de la manera que se ve en la siguiente imagen:
En la imagen anterior se observa que hemos asignado marcas a textos e imágenes de la página objeto de mejora. El siguiente paso es generar ese texto enriquecido (parte del mismo se resalta en la imagen siguiente en la subventana de la derecha).
Lo siguiente que hemos de hacer es descargar ese texto y usarlo para sustituir el de la página original (la que no tiene datos estructurados). Transferir esa nueva página a la web académica de la Universidad de Murcia y dejar al motor Google un tiempo prudencial para que la reindexe y podamos comprobar si hay algún efecto sobre el ‘snippet’.
Gerry McGovern escribió en New Thinking sobre los problemas de «ego» en las organizaciones y cómo están acabando con la confianza que un sitio web transmite a sus visitantes. Pone como ejemplo la web de una organización ya de por sí no muy estimada – el Fondo Monetario Internacional – dirigido (tanto en la realidad como en su sitio web) por la política francesa Christine Lagarde.
Es muy posible que la vista de la página que tenía el autor en diciembre de 2014 no sea exactamente la que reproducimos ahora unos meses más tarde. El tema de diseño elegido dedica un porcentaje importante de la pantalla a un carrusel de diapositivas (cinco en este caso) que enlazan con distintos temas de interés para los responsables de esta web. La primera de ellas es la que estamos viendo, dedicada a una intervención de la directora del este organismo ante el Consejo Atlántico (la más alta autoridad de la OTAN) y cuyo vídeo también podemos visualizar rápidamente porque ocupa uno de los cuatros «subtemas de interés» que se presentan en formato de recuadro en el centro de la pantalla. Pero está claro que la visita que hizo el autor en diciembre no debió de satisfacerle especialmente:
«Dominando la página aparece la jefa del FMI, Christine Lagarde, con una gran foto de sí misma. En lenguaje imperativo se informa que Lagarde acoge con satisfacción el compromiso del grupo G-20 de las economías avanzadas y emergentes para intensificar los esfuerzos en el impulso del crecimiento económico y la creación de puestos de trabajo. Esta arcaica redacción está fuera de paso con el mundo de los medios sociales. Esto no es excepcional, si usted visita, por ejemplo, la página de Bangladesh, leerá títulos como: «Comunicado de Prensa: Declaración de Subdirector Gerente del FMI Naoyuki Shinohara, al término de su visita a Bangladesh». Como usted puede observar fácilmente, se trata de una verdadera Realeza FMI, .todo en cuanto al FMI se refiere a la página web, el mundo y el universo es todo acerca de ellos. No se trata de lo que el cliente quiere hacer, sino qué cosas increíbles están haciendo los funcionarios imperiosas del FMI (sin saber muy bien para qué, esto lo añado yo). Lo dicho: un desenfrenado ego«.
Recreación con IA de la página comentada (la original es de 2014).
Estamos ante un caso muy claro de ausencia de comunicación entre la organización y su entorno. Este organismo internacional (o quizá «supranacional» podríamos decir porque las naciones le importan lo justo, especialmente sin son pobres y mediterráneas), no considera que su sitio web pueda ser la puerta de entrada para que gobiernos y otras instituciones puedan interaccionar con ellos. No, para ellos, el sitio web es su escaparate donde ellos pueden mostrar lo buenos e inteligentes que son, aunque luego dediquen la mitad del año a justificar por qué han fallado las previsiones que habían realizado durante la mitad del año anterior. El FMI reproduce en su sitio web uno de los principales problemas con los que deben lidiar los gestores de información a la hora de diseñar la arquitectura de una sede web, no reproducir la estructura de poder orgánico de la organización en la sede web («egos» les llama McGovern), porque eso no va a aportar nada positivo para la experiencia de sus usuarios.
«Esa es la naturaleza de las grandes organizaciones, qué vamos a decir de ello ahora. La gestión de la cadena es de más arriba hacia abajo y del ego más grande al menor en ese sentido. Es cierto que así es el camino organizacional seguido desde los tiempos de los emperadores de Roma o de los faraones de Egipto. Pero lo que es diferente hoy en día es cómo vemos a las organizaciones. Muchas organizaciones no han cambiado, pero las personas y la sociedad sí, de hecho, cada día que pasa, dejamos de confiar en más organizaciones«.
Prosigue el autor citando diversas estadísticas sobre esa pérdida de confianza en los gobiernos a la que estamos asistiendo en la última década especialmente y que está propiciando cambios en los modos de funcionamiento de la sociedad (y esperemos que en las urnas cuando nos toque ejercer nuestro derecho al voto). Y esa pérdida de confianza es poliédrica, afecta en varios planos y a muchos sectores, los medios de comunicación incluidos (en algunos estudios resultan menos fiables que los bancos, que ya es decir). ¿A qué se debe esa falta de confianza en los medios de comunicación?
«La gente se ha vuelto más educada. Atienden a sus iguales más de lo que atienden a los líderes. Las organizaciones han abusado enormemente de la confianza que la gente les había conferido. Tengamos en cuenta que entre 1990 y 2010, el sueldo medio de un CEO creció un 533%, según Business Week, mientras que el salario de un trabajador ordinario creció un 32% Desafortunadamente, muchos directivos parecen pensar que la organización es un reino del más allá y que el resto estamos para servirles. En lugar de que el sitio web del FMI se centre en sus clientes, se centra en sus jefes. La página de inicio se convierte en una página de inicio para Christine Lagarde, con las otras páginas asignadas a los otros príncipes. El contenido web dice mucho acerca de quién eres en realidad y lo que realmente piensas. Un contenido web centrado (focalizado) en el cliente ayuda a las personas en sus tareas. Un diseño centrado en la destrucción de la confianza hacia la organización es un diseño centrado en los egos. No busca justificar o complacer, el mundo ha cambiado, pero muchas organizaciones todavía están atrapadas en una mentalidad medieval. Sus egocéntricas sedes web son anuncios y por ello no merecen confianza. Domar el ego es el primer paso en la reconstrucción de la confianza«.
Diseño web centrado en el usuario: flujo de pasos.
Más allá de las consideraciones de tipo sociológico que emplea McGovern para criticar el planteamiento general de diseño de esta sede web (que es un buen ejemplo de otras muchas similares), queremos recordar la idea del Diseño Centrado en el Usuario, marco metodológico que (citando a Norman y Draper, 1986) nos presenta Hassan Montero y que podemos ver en la imagen anterior.
Retomamos el análisis de la «tabla periódica del SEO» que ha elaborado Search Engine Land prestando nuestra atención en el código HTML con el que se elaboran las páginas, factor que siempre ha aparecido como importantes en todas las recomendaciones elaboradas para obtener un buen posicionamiento de nuestro sitio web.
Ht:la etiqueta del título (<TITLE>): al igual que si escribiéramos 100 libros no le podríamos el mismo título a cada uno de ellos sino que buscaríamos las palabras que mejor describen. el contenido de cada obra, lo mismo hemos de hacer con el título de la página web que estemos editando (tampoco vale asignarle un título vago o genérico, el problema es similar). El contenido de esta etiqueta es tan valorado por los motores de búsqueda que alguno de ellos, Google en concreto, si no lo considera adecuado lo cambia antes de almacenar la página en sus índices. El peso de esta etiqueta es +3 y si alguien quiere profundizar en esta cuestión, puede consultar el tutorial Writing HT;L Title Tags for Humans, Google & Bing elaborado también por Search Engine Land. Su peso es +3.
Hd: la meta-etiqueta de descripción: como pasa con la etiqueta del título es un factor siempre tenido en cuenta a la hora de elaborar recomendaciones para los webmasters. Algunos puristas del SEO pueden decir que esta meta-etiqueta no «describe» propiamente hablando en términos de recuperación de información sino que sirve para «presentar» la información dentro de la lista de sitios recuperados por un motor. Es cierto, lo que no le quita ningún valor a la misma y puede servir para aumentar el número de visitas a la página por la subjetividad del usuario que consulta la lista de respuestas y se puede sentir atraído por una correcta descripción frente a una genérica. Al igual que ocurre con el elemento anterior, los motores de búsqueda pueden llegar a modificarla si lo consideran oportuno. Su peso es +2.
Hh: las etiquetas de los encabezados y subencabezados. Otro factor suficientemente conocido y presente en la mayoría de guías y recomendaciones para los diseñadores de sitios web. Además de establecer una secuencia lógica en la estructura de los mismos dentro de una página (es decir, no pasar de un encabezado de nivel a uno de nivel cuatro sin hacer uso del encabezado de nivel 3), estas etiquetas sirven para definir secciones en una página y, por tanto, cumplen una función parecida a la etiqueta del título de la página: «nombran» a la sección de la página. Por ello hay que llevar cuidado especial a la hora de elegir las palabras que representen el contenido de esas secciones. Su peso es algo inferior: +1
Hs: datos estructurados: todo lo que tiene que con los microdatos, microformatos y schema.org ayuda sin duda alguna, al motor de búsqueda (y a sus usuarios) en el acceso a la información. No está del todo claro si son factores directos de éxito para el posicionamiento pero su importancia está ahí y debe ser tenida en cuenta. Su peso es +1
Sistemas de búsqueda, tesauros y vocabularios controlados.
Estos «pilares» tienen algunas correspondencias en la Tabla Periódica del SEO, son las siguientes:
Ac: «recopilabilidad» del sitio web (‘site crawlability‘). Sabido es que los motores de búsqueda recopilan sitios web a partir de una serie de direcciones «semillas» desde las cuales inician sus rastreos e indexan todo el contenido de estas páginas, además de ir anotando todos los enlaces que en ellas vayan encontrando, tanto a efectos de mejor posicionamiento como para aumentar el tamaño de la colección del índice de los motores. Es uno de los factores más considerados, de hecho se le ha asignado un valor de +3 en la tabla. Si se desea atraer tráfico a un sitio web es fundamental (e incluso vital) que los elementos que forman parte del mismo no generen problemas a estos módulos recopiladores (los robots o ‘crawlers’ de los motores de búsqueda). La mayoría de los sitios en general no tienen problemas de rastreo, pero siempre hay cosas que pueden causar problemas y que, muchas veces nos pasan desapercibidas. Por ejemplo, el uso de las tecnologías JavaScript o Flash potencialmente pueden hacer invisible para los robots los vínculos presentes en las páginas y así haremos más complicado un rastreo profundo de nuestro sitio web. Cada sitio Web se beneficia de un presupuesto de rastreo, es decir, de una cantidad aproximada de tiempo o número de páginas que un motor de búsqueda rastreará cada día: Ese presupuesto será de mayor valor cuanta más confianza y autoridad reconocida tenga en nuestro sitio (y los elementos del diseño influyen en ello decisivamente). Los sitios más grandes pueden tratar de mejorar su eficiencia de rastreo para garantizar que las páginas «correctas» están siendo rastreadas con mayor frecuencia. El uso de robots.txt , estructuras de enlace internos e indicar de forma explícita a los motores de búsqueda no rastrear páginas con ciertos parámetros de URL, por ejemplo, pueden mejorar la eficiencia del rastreo. En la mayor parte de las ocasiones, los problemas de rastreo se pueden evitar fácilmente, destacando especialmente el uso de sitemapsporque tanto HTML como XML lo aprovechan para hacer más fácil a los motores de búsqueda el rastreo.
Ad: Duplicación / Canonicalización (‘Duplication / Canonicalization‘). A veces, el índice del motor de búsqueda se complica especialmente cuando, tras una operación de selección de información, se localiza un conjunto de páginas con contenido prácticamente similar (algo desgraciadamente frecuente en los blogs con un alto índice de copia directa de contenidos) y el algoritmo de ranking se encuentra con problemas para discernir cuál de esas muchas páginas es la más relevante para la necesidad de información planteada. Esto no es bueno (y ya hemos visto en este blog que, por ejemplo Google, lo penaliza por la vía de sus algoritmos Penguin y Panda).
As: Velocidad de descarga (‘site speed’). El interés por la velocidad de acceso al contenido de un sitio web es tal que Google ha declarado que aquellos sitios más rápidos tendrán una pequeña ventaja en su algoritmo de alineamiento (si bien será uno más de los muchos factores que emplea Google) Eso sí, cuando diseñamos una página pensando en su velocidad de descarga, también estamos mejorando de forma indirecta otros factores que contribuirán, sin duda alguna, a mejorar el posicionamiento de la misma. Por tanto, es algo importante a tener en cuenta.
Au: URL descriptiva. Si bien no es un factor decisivo, desde siempre se ha recomendado que en la dirección del sitio web (URL) aparezcan la palabra o las palabras que mejor lo representan (por ejemplo, un blog sobre turismo en Tarifa podría tener una URL como turismoentarifa.com). Eso siempre ayuda y además, parece que a los usuarios de la web les aportan más confianzas estas URLs tan «concretas» en lugar de algunas algo más «difuminadas». También es conveniente que la URL indique el objeto principal del sitio web a la hora de presentar los datos estructurados en los resultados de la búsqueda, tal como hacen los motores.
Por lo tanto, observamos que guardar siempre una serie de buenos hábitos sobre la arquitectura del contenido de nuestro sitio web es positivo (y nunca negativo como dirían seguramente Van Gaaly un innombrable ex-entrenador del Real Madrid) para nuestro posicionamiento. Son pequeños detalles que siempre ayudan. El gusto por la vida, ya se sabe, es cuestión de detalles ..
La recuperación de información, como disciplina claramente diferenciada de la recuperación de datos, posee una naturaleza no determinista que provoca ineludiblemente ciertas dosis de incertidumbre a la hora de realizar una operación de búsqueda. Es por ello que, desde el inicio del desarrollo de esta disciplina, ha sugerido una considerable cantidad de propuestas de medida de la efectividad del funcionamiento de los sistemas encargados de esta tarea: los sistemas de recuperación de información (SRI). La consolidación de la World Wide Web como ejemplo paradigmático del desarrollo de la Sociedad de la Información y del Conocimiento, y la continua multiplicación del número de documentos que en ella se publican cada día, propicia la creación de los sistemas de recuperación de información más avanzados, de mayor volumen de documentos gestionados y de mayor popularidad: los motores de búsqueda.
En estos sistemas, no obstante, subyacen las dudas sobre su efectividad, máxime cuando los mismos suelen ofrecer grandes cantidades de referencias entre las cuales abundan muchas poco relevantes con la necesidad de información del usuario. La evaluación de estos sistemas ha sido, hasta el momento, dispersa y dispar. La dispersión procede de la poca uniformidad de los criterios empleados y la disparidad surge de la aperiodicidad de los estudios y por la diferente cobertura de los mismos. Surge entonces la necesidad de proponer el desarrollo de un modelo de evaluación multidimensional de estos sistemas, próximos a los usuarios y al contexto donde se desarrolla, la World Wide Web, entorno difícil de gestionar y que, además, se encuentra afectado de grandes dosis de volatilidad. Nuestra propuesta de modelo de evaluación adapta medidas empleadas en otros procesos de la misma naturaleza, basadas en los juicios de relevancia y en la detección de errores y/o duplicados e implementa una función discreta de ponderación de la relevancia de los documentos recuperados.
Mención de Responsabilidad: / Francisco Javier Martínez MéndezRodríguez Muñoz, José Vicente (Profesor Titular de Universidad de Ciencias de la Información, Universidad de Murcia)
Publicación: Alicante : Biblioteca Virtual Miguel de Cervantes, 2003
Nota General: Calificación de la tesis : Sobresaliente cum laude