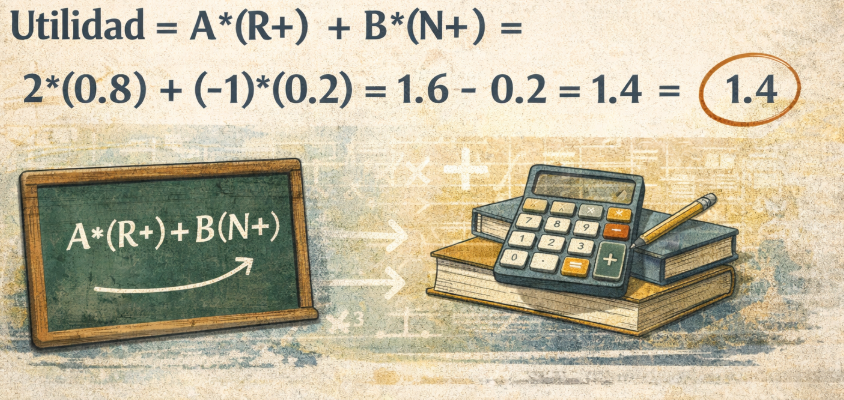Lo normal sería contestar que no a esa pregunta, pero tras leer el trabajo ‘The ranking algorithm of Yahoo‘ en el sitio web A promotion guide, comienzo a tener mis dudas (más o menos las mismas que tiene el autor del trabajo). En el artículo se recoge un pequeño experimento conducente a intentar establecer cuáles de los parámetros que normalmente afectan al posicionamiento son verdaderamente empleados por Yahoo Search!. Ya en el planteamiento del trabajo el autor presenta la posibilidad de que este buscador use el algoritmo Pagerank de una página como elemento del posicionamiento.
Vuelvo a la carga con el tema de los metadatos. Ya prometí en su día «embeberme» de toda esa metacultura y convertirme en un defensor a ultranza de la misma, pero lo cierto es que estoy fracasando en el intento. Otro día podré contar una «meta-experiencia» que estamos «meta-viviendo» en estas fechas y lo cierto es que no es para repetirla, pero vamos en la vida todo es posible, así que a esperar. Pues bien, ahora más en serio, ayer en la web Google Dirson posteaban lo siguiente:
¿Seguirán funcionando los tags en un futuro?
«[05-12-2005] Muchos servicios que almacenan información de diferentes tipos, como Flickr (fotografías), Technorati (posts de blogs), ‘del.icio.us’ (enlaces) o YouTube (vídeos), utilizan los populares ‘tags’ (‘etiquetas’) para intentar ordenar los contenidos y conseguir que los elementos sean fácilmente localizables.
Por ejemplo, podemos encontrar fotos sobre Paris en Flickr (utilizando el tag ‘paris’), posts que hablen sobre la Xbox en Technorati (con el tag ‘xbox’), vídeos de skate en YouTube (tag ‘skateboard’), o incluso cuáles son los tags más populares en ‘del.icio.us’ que da una idea de qué temas interesan más en la WWW.
Sin embargo, ¿por qué deben los usuarios perder unos segundos escribiendo unas palabras sobre las que tratan sus contenidos? ¿Y si no las escriben todas? ¿Y si las escriben mal? Por ejemplo, si buscamos ‘surf’ en Flick, no aparecen muchas de las fotografías que se muestran si buscamos ‘surfers’, cuando la temática es la misma. La tecnología de los tags es similar a la que utilizaban aquellos ‘viejos buscadores’ que nos pedían que insertásemos «cinco palabras clave separadas por comas» cuando queríamos dar de alta nuestra URL.
¿No puede ser el propio servicio el que determine los temas que contiene la fotografía, vídeo, post, etc? Quizá nos falten algunos años de investigación tecnológica (ya hemos hablado sobre las búsquedas de ‘tercera generación’ o sobre herramientas como Riya que reconocen elementos dentro de las imágenes), pero -como dice John Battelle en este artículo- las tags no son el futuro.»
Imagino que la frase «las tags no son el futuro» quiere decir que los autores de las páginas web seguiremos sin hacer uso de las metaetiquetas, que los metadatos tendrán que formar parte de los recursos electrónicos en otra parte del documento y finalmente, que los metadatos por supuesto se generarán solitos ya que los autores no están muy «por perder unos segundos» de sus atareadas y globalizadas vidas.
Aunque el panorama es triste, peor lo pone la frase, porque si uno la lee del tirón y no reflexiona, puede llegar a pensar que no podremos implantar un metadato Dublin Core en las páginas web porque van a desaparecer las tags («etiquetas»). Con esa forma de expresión y con el contenido de la misma, no es de extrañar que los motores de búsquedas «pasen literalmente» de los metadatos.
Uno de los libros fundamentales sobre recuperación de información es la obra ‘Language and representation in information retrieval’ de D.C. Blair de 1990. Y una de sus principales aportaciones es, sin duda alguna, el llegar a establecer una clara diferenciación entre el término ‘data retrieval’ y el término ‘information retrieval’, utilizando como criterios distintivos:
En recuperación de datos se usan preguntas altamente formalizadas, cuya respuesta es directamente la información deseada. En cambio, en recuperación de información las preguntas resultan difíciles de trasladar a un lenguaje normalizado (aunque existen lenguajes para ello son de naturaleza mucho menos formal que los empleados en los sistemas relacionales) y la respuesta es un conjunto de documentos que pueden contener, sólo probablemente, lo deseado, con un evidente factor de indeterminación.
De lo anterior y según la relación entre el requerimiento al sistema y la satisfacción de usuario, la recuperación de datos es determinista y la recuperación de información es posibilista, por causa del nivel de incertidumbre presente en la respuesta.
En cuanto al éxito de la búsqueda, en recuperación de datos el criterio a emplear es la exactitud de lo encontrado, mientras que en recuperación de información, el criterio de valor es el grado en el que la respuesta obtenida satisface las necesidades de información del usuario, es decir, su percepción personal de utilidad, más conocido como la relevancia de la respuesta..
Jesús Tramullas destaca un aspecto de las reflexiones de Blair, “la importancia, en ocasiones ignorada, que tiene el factor de predicción. Predicción por parte del usuario, ya que éste debe intuir, en numerosas ocasiones, los términos que han sido utilizados para representar el contenido de los documentos, independientemente de la presencia de mecanismos de control terminológico. Este criterio de predicción es otro de los elementos que desempeñan un papel fundamental en el complejo proceso de la recuperación de información” y que no se presenta en el campo de la recuperación de datos.
Seguimos intentando convencernos de las ventajas del uso de los metadatos. El otro día, buscando en Google por «metadatos» y «usabilidad» me encontré un trabajo con la siguiente frase al comienzo:
Supongo que algunos ya saben que el autor de esta frase es el profesor e investigador Ricardo Baeza-Yates en el artículo titulado «Ubicuidad y Usabilidad en la Web» escrito en 2002. El mismo introduce la idea de que un sitio web “bueno” no se define únicamente por su estética, sino por una secuencia de condiciones necesarias para que el usuario llegue a usarlo y, sobre todo, vuelva a visitarlo. El autor parte de un princicio claro: la web crece a un ritmo tan acelerado (y con tanta renovación de páginas) que es imposible pensar que todos los sitios van a ser diseñados por especialistas en interfaces. De ahí se desprenden tres salidas: (1) facilitar que se diseñen sitios razonables sin ser experto; (2) formar a más gente en diseño o (3) resignarse a un ecosistema web difícil de usar. Mediante la analogía con una tienda física, Baeza-Yates explica que la desorganización, la mala ayuda y la dificultad para encontrar lo que se busca llevan al abandono del sitio, algo frecuente en cualquier ámbito, no solo en comercio electrónico.
El éxito de una página depende de su facilidad de uso y de localización
Sobre esa base, el artículo articula dos conceptos clave en la web: ubicuidad y usabilidad. Primero, un sitio debe ser “ubicuo”: poder ser encontrado y accedido. La ubicuidad se descompone en buscabilidad (que el sitio sea localizable, especialmente a través de buscadores) y visibilidad (que el sitio pueda verse y cargue adecuadamente en condiciones técnicas diversas). Esto implica acciones concretas: asegurar que los buscadores puedan rastrear el sitio (registro, enlaces entrantes, evitar barreras como Flash, mapas de imagen, ‘frames’ o JavaScript mal usado), cuidar el vocabulario de la página principal para que coincida con los términos de los usuarios, y mejorar la posición con enlaces y metadatos (con cautela por el “spam” de metadatos). La visibilidad, por su parte, exige ligereza (tamaños moderados), compatibilidad con distintos navegadores y sistemas, y atención a la accesibilidad (WAI), recordando que los robots de búsqueda “son ciegos” y que los enlaces textuales ayudan a usuarios y buscadores.
Después, una vez que el sitio se encuentra y se ve, entra la usabilidad, definida (Norma ISO 9241-11) como efectividad, eficiencia y satisfacción en un contexto de uso. Se revisan atributos clásicos (aprendizaje, velocidad, errores, retención, satisfacción) y otros complementarios (control, apoyo a habilidades, privacidad). Finalmente, se expone la ingeniería de usabilidad y la evaluación como núcleo del proceso: inspecciones, pruebas con usuarios, pensar en voz alta, evaluaciones heurísticas, caminatas cognitivas y encuestas. El texto culmina con heurísticas y recomendaciones prácticas (consistencia, prevención de errores, diseño minimalista, rapidez, compatibilidad, diseño para diversidad, escritura concisa), subrayando que la verdadera meta es la fidelidad del usuario: que encuentre, use, se “seduzca” y regrese.
Cuenta Donna K. Harman en el capítulo séptimo de ‘TREC: Experiment and Evaluation in Information Retrieval‘ que a partir de la conferencia TREC-3 comenzaron a probarse distintos sistemas de recuperación de información implementados en colecciones de documentos multilingües. Hasta ese momento, como es fácil suponer solo se había empleado el Inglés.
En esa conferencia, cuatro grupos trabajaron con una colección de 58.000 documentos procedentes de un periódico de Monterrey llamado El Norte (aproximadamente 200 megabtytes de tamaño). Los grupos usaron búsquedas simples y analizaron el comportamiento del sistema con un total de 25 preguntas. Algunos de estos grupos (de las universidades de Cornell y Amherst -Massachusetts), trasladaron sus sistemas directamente, con la única salvedad de los ficheros de palabras vacías que ahora iban a ser términos en español. Los otros dos grupos (Dublin -«la del Core»- y Michigan) usaron desarrollos adaptados al nuevo idioma, modificando la primera de ellas el original algoritmo de lematización (‘stemming‘) propuesto por Porter.
El principal resultado de este experimento fue la facilidad de portabilidad de las aplicaciones y técnicas de recuperación de información a textos escritos en otro idioma, el nuestro en este caso. En el informe de la Universidad de Cornell se decía que bastaban unas pocas horas de trabajo para garantizar la misma efectividad de los sistemas. Estas conclusiones iniciales fueron refrendadas posteriormente en las conferencias TREC-4 y TREC-5. La inmortal lengua de Miguel de Cervantes está al mismo nivel que la de Shakespeare, por tanto.
Esta medida esencialmente asume que la presencia de documentos relevantes en la respuesta de un sistema de recuperación de información a una determinada pregunta debe tomarse como un rédito a favor del sistema, al mismo tiempo que los documentos no relevantes deben considerarse como un débito. Por lo tanto, esta medida establece su valor favoreciendo el acierto y penalizando al mismo tiempo el desacierto. Su cálculo es muy intuitivo, se multiplica por un factor (A) el porcentaje de documentos relevantes (R+) y a este producto se le suma el producto de un segundo factor (B) por el total de documentos no relevantes (N+). Como el segundo factor es de penalización su valor es negativo, por lo tanto más que sumar se resta. Así, si en una búsqueda determinada, nuestro buscador devuelve un 80% de documentos relevantes (por tanto, un 20% de no relevantes), los valores de R+ y N+ serían 0.8 y 0.2 respectivamente.
Ahora queda por establecer los valores de los factores A y B, que son introducidos por el evaluador según estime oportuno. En las conferencias TRECs 9-11 se optó por utilizar A=2 y B=-1, asumiendo que la posibilidad de recuperar un documento relevante era del 66% y de encontrar un documento no relevante era del 33%, de ahí que el valor absoluto de A sea el doble que el de B. Con estos parámetros, nuestra búsqueda ejemplo tendría el siguiente valor de utilidad lineal que podemos vers de forma esquemática en la figura siguiente:
Cálculo de la utilidad lineal ilustrado.
Esta utilidad indica que la búsqueda es buena, algo que así parecía al tener un 80% de documentos relevantes, cuya influencia en la medida refuerza esta fórmula. Lo cierto es que quizá (solo quizá) a veces nos complicarnos mucho la cabeza a la hora de establecer una medida de evaluación de la recuperación de información. De hecho, en TREC-8 los autores experimentaron con una ‘utilidad no lineal’ que resultó difícil de interpretar y fue deshechada.
El trabajo explica de forma divulgativa y rigurosa el fundamento matemático que subyace al éxito del buscador Google, centrado en su algoritmo de alineamiento PageRank, cuyo núcleo conceptual se basa en el álgebra lineal. El autor parte de la constatación de que Google se consolidó rápidamente como buscador dominante no solo por la cantidad de información indexada, sino, sobre todo, por la calidad del ordenamiento de los resultados de búsqueda, que difiere de enfoques basados únicamente en la coincidencia de términos.
El artículo concibe a la web como un grafo dirigido, en el que las páginas son los nodos y los enlaces hipervinculados representan aristas. Desde esta perspectiva, la relevancia de una página no depende solo de su contenido, sino del número y la calidad de las páginas que enlazan hacia ella. Esta idea se formaliza mediante una matriz que representa las probabilidades de transición entre páginas, interpretando la navegación de un usuario como un proceso estocástico. El valor de PageRank de una página se define entonces como la probabilidad de que un “navegante aleatorio” se encuentre en ella tras un número elevado de pasos.
Fórmula de Pagerank ilustrada
En esencia, el algoritmo se basa en un cálculo que permite identificar qué páginas son más importantes dentro de toda la red, a partir de la estructura de enlaces que las conectan entre sí., lo que conecta directamente el problema con conceptos clásicos del álgebra lineal, como matrices, autovalores, autovectores y convergencia. El autor explica cómo la introducción de un factor de amortiguación garantiza la existencia y unicidad de la solución, evitando problemas como ciclos cerrados o componentes desconectadas del grafo.
Finalmente, el trabajo subraya el valor didáctico del PageRank como ejemplo de aplicación real del álgebra lineal, mostrando cómo herramientas matemáticas abstractas pueden resolver problemas prácticos de gran escala. Más allá de Google, el artículo pone de relieve la importancia de los modelos matemáticos en la recuperación de información y en el análisis de redes, anticipando su relevancia en ámbitos como la ciencia de datos, la web semántica y los sistemas de recomendación.
Esta mañana recibía el agradable comentario que os acompaño:
«Hola, javima: Un grupo de amigas estamos buscando información sobre diseño paginas web cuando encontramos tu blog. Tu título, Textffiles: memoria de Internet., nos ha gustado y lo hemos comentado. Estamos tratando de escribir algo relacionado con diseño paginas web para un proyecto de internet. Muchas gracias por permitirnos aprender de ti con tu excelente blog.»